World’s 1st byte-level AI models: Bolmo 7B and 1B explained, how are they different
Bolmo byte-level AI models explained: tokenizer-free language processing breakthrough
Allen Institute Bolmo models challenge tokenized LLMs with raw byte processing
How byte-level AI models differ from Bolmo 7B to 1B

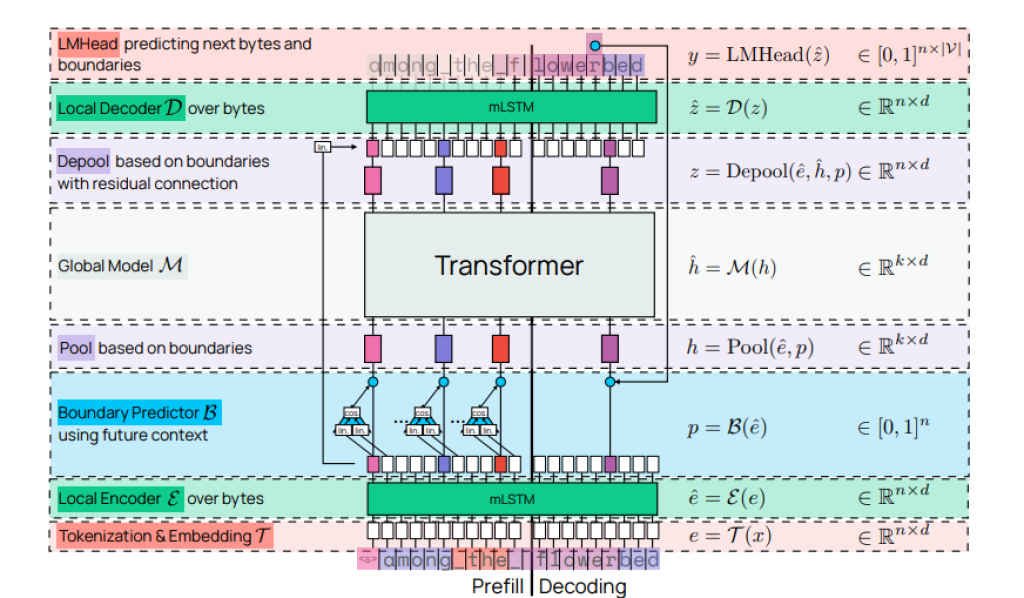
The Allen Institute for AI (Ai2) has released Bolmo, a new family of AI models that represents a shift in how machines can process language. While byte-level architectures like ByT5 and Byte Latent Transformer have existed in research circles, Bolmo 7B and 1B are distinct as the first fully open model family to implement this approach competitively at these parameter scales.
This release addresses specific limitations found in standard Large Language Models (LLMs) such as Llama or GPT. By removing the tokenizer and reading raw text as bytes, these models offer a robust alternative for handling noisy data and languages that are often underrepresented in standard token vocabularies.
Also read: AI agents to India’s internet boom: Cloudflare highlights 5 epic things of 2025
The Byte-Level Approach
Standard LLMs do not read text character-by-character. They rely on a tokenizer which breaks text into chunks called tokens based on a fixed vocabulary. This works well for standard English but can be brittle when facing typos or rare words that fall outside that list.
Bolmo eliminates the tokenizer. It reads raw UTF-8 bytes directly. Its vocabulary consists of the 256 possible values of a byte. This allows the model to process the atomic structure of data without relying on a pre-defined dictionary. The result is a model that is natively robust to spelling errors and “noisy” text because it cannot encounter an “unknown” token. The researchers achieved this by adapting existing high-performance models using a technique called “byteification,” effectively retrofitting a byte-level input mechanism onto a standard transformer architecture.
Also read: I took a 10000mAh MagSafe power bank on vacation, and it wasn’t from Apple
Comparing Bolmo 7B and 1B
The two models in this release differ primarily in their base architecture and intended scale.
Bolmo 7B is the larger and more capable model. It was adapted from the Olmo 3 7B base. Because it builds upon the newer Olmo 3 architecture, it retains strong general-purpose capabilities. In benchmarks, it demonstrates that a byte-level model can achieve performance parity with standard token-based models of the same size, while showing particular strength in tasks requiring character-level manipulation.
Bolmo 1B is the smaller variant, derived from the Olmo 2 1B base. Its smaller parameter count makes it significantly faster and less computationally intensive to run. While it does not share the same advanced base architecture as the 7B version, it provides a functional entry point for byte-level processing on hardware with limited resources.
A Viable Alternative
The significance of Bolmo is not that it renders tokenizers obsolete, but that it proves tokenizer-free models can be competitive. The documentation shows that these models do not suffer the significant performance penalty often associated with byte-level processing in the past. They offer developers and researchers a functional, open-weight option for applications where standard tokenization fails, such as processing garbled text, complex code strings, or highly morphological languages.
Also read: NVIDIA powers the agentic era: The Nemotron 3 debut explained