Encoder-Free AI explained: The architecture behind Google’s Gemma 4 12B

A vast majority of multi-modal AI systems function as a relay race. For example, an image will come in through the Vision Encoder, be transformed into a language the Language Model understands and passed on. The same thing happens with audio; it passes through Audio Encoder and then gets passed onto the main system. While that works, it feels like it is a temporary workaround to an original design that was only text-based.
Also read: Meta Business Agent: Is your data private, who does it work for?
Google has created a new system called Gemma 4 12B which eliminates the relay race and has one large unified Transformer backbone that is used for all three types of inputs (text, image, and audio), eliminating passing around between the encoders. While this may seem like a small change; it truly represents a monumental shift in the technology.
What actually changed
Google simplified things for vision by swapping out the old encoder for a lighter version. This consists of a single matrix multiplication, positional embeddings, and normalization layers. So, the LLM backbone does its own visual processing – something no one anticipated from earlier models. They went further with audio, cutting out the encoder completely. Raw audio becomes a direct projection into the same space as text tokens. Spoken and typed words now arrive at the model exactly the same way.
Also read: At Build 2026, Mustafa Suleyman finally revealed Microsoft’s AI moves
This isn’t just cleaner coding; it represents a shift in how we think about what language models can do fundamentally.
Why this actually matters
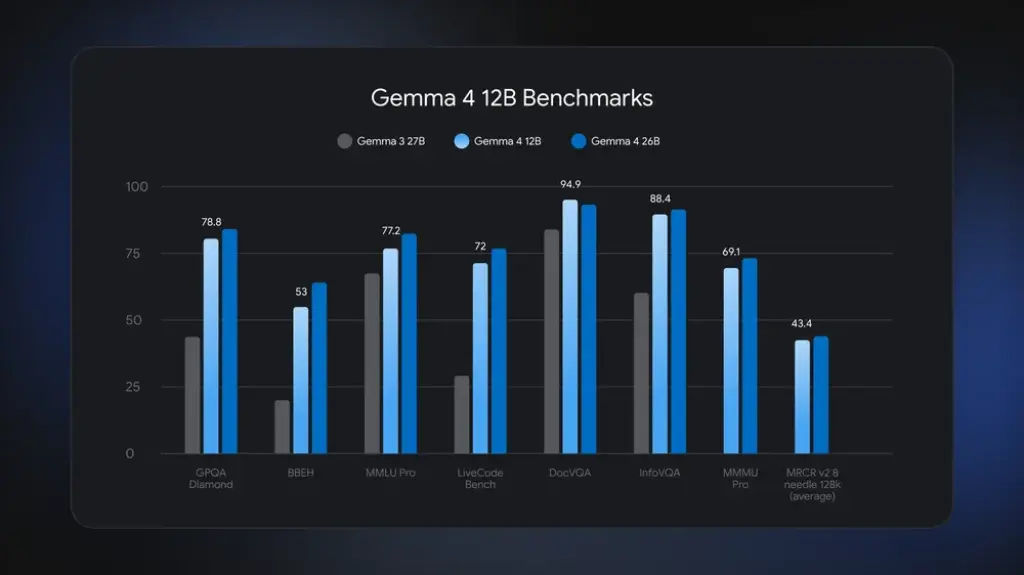
Encoding techniques come with a cost; not only do they take up space in memory – they also introduce additional delay and increase overall system resource consumption, making it much more challenging to deploy. When Google removed Gemma 4 12B encoders, the total memory requirements for this model dropped to the same levels found in consumer laptops (16GB of video memory). Despite this significant decrease in the size of the model, performance results were very close to that of the larger (26B) Mixture of Experts (MoE) model.
The two models demonstrated near frontier-level performance relative to their ability to reason across multiple modalities (sight, sound, etc.) and would be available to anyone with access to a laptop computer (without needing to use cloud-based services). I think that the next logical question would be whether this approach (using an encoder-less model with only the backbone layer) would work as well at 12B (it does). My bigger question relates to whether or not this particular architecture/philosophy will scale beyond 12B. The architecture/philosophy of using an encoder-free design utilizes the assumption that if a large enough backbone exists to interpret the raw sensor data directly, there will be no reason to create translator (aka special-purpose) layers.
Thus, all the intelligence is within the backbone layer and not distributed throughout the entire model. The answer could be either an insightful breakthrough or an inherent limitation of the architecture as we continue scaling to larger sizes (greater than 12 billion parameters). The existence of a “seeing, hearing and reasoning” type of model is definitely enough to get your attention; however, regardless of the underlying architecture, the performance of both of these models continues to be evidence that they work.
Also read: OpenAI, Anthropic, and Google sign letter to stop AI-enabled bioweapons, here’s why it matters