India AI Impact Summit 2026: BharatGen Param 2, SarvamAI, and the rise of Indian LLM models so far

India’s AI ecosystem has been on a steady growth in the last few years. Both public initiatives and private startups are working in this stream. From the early days of experimentation and scattered projects, we now have sovereign AI models trained on Indian datasets that reflect the country’s linguistic diversity, regulatory frameworks and cultural nuances. There are also application-ready models for enterprises and specialised tasks. We have listed the leading indigenous Large Language Models (LLMs) that are shaping how generative AI (GenAI) will be used in the country. These are listed in no particular order.
BharatGen Param 2
BharatGen is a government-led company for sovereign, multilingual models. It launched as an IIT Bombay consortium initiative with strong academic backing in 2025. It aims to develop LLMs that understand India’s languages, legal frameworks and cultural contexts. It recently launched Param 2, a 17-billion-parameter multilingual foundation model with Mixture of Experts (MoE) architecture. The model is trained for 22 Indian languages.
For Indians, this could mean better AI tools in local languages, improved access to government schemes, and models aligned with local laws and cultural context rather than imported assumptions. The project sits inside a wider national mission to build homegrown AI capabilities and reduce dependency on foreign models and cloud infrastructure.
Sarvam AI: Sarvam Vision and Bulbul V3
Sarvam AI positions itself as a full-stack AI platform, making ‘AI that gets India.’ The company has been visible at national AI events as a flagship private player. Recently, we got to see its Sarvam Kaze smart glasses as the first Made-in-India product of this ilk. As for AI models, there are two launches so far: Sarvam Vision and Bulbul.
Sarvam Vision is a vision-language/document intelligence system focused on optical character recognition (OCR) and layout understanding for Indian documents. It is a 3 billion-parameter model designed for mixed-script text, scanned forms, handwriting and complex layouts, across 22 Indian languages plus English. On the olmOCR-Bench, Sarvam Vision scored 84.3 % accuracy, outperforming global systems such as Google’s Gemini 3 Pro, OpenAI’s ChatGPT and DeepSeek OCR v2 on multi-script and complex document recognition. On OmniDocBench v1.5, it reportedly achieved 93.28% accuracy on real-world layouts with tables and formulas.
Bulbul V3 is an advanced text-to-speech (TTS) system built on an underlying language model to generate natural, expressive speech. It has been trained on Indian data and works with 11 Indian languages, including English with an Indian accent. It supports 30+ distinct speaker voices with control over features such as pace, tone and expressivity. In the current API, there is access up to 2500 characters per request. The compatible output formats are MP3, WAV, AAC, OPUS, and FLAC with selectable sample rates from 8 kHz to 48 kHz, which can be used for both telephony (voice agent) and high-fidelity use cases.
Also Read: Yotta’s 2 billion dollar NVIDIA supercluster puts India on global AI map
Gnani.ai Inya VoiceOS
Gnani.ai has introduced Inya VoiceOS, a 5 billion-parameter voice-to-voice foundational AI model. Unlike conventional speech systems that convert audio to text and back again, Inya VoiceOS processes and generates speech natively in acoustic and semantic space, removing intermediate transcription steps. It is trained on more than 14 million hours of multilingual speech data and fine-tuned with over 1.2 million hours of task-specific audio, supported by 8 trillion text tokens for robust linguistic reasoning. The model delivers 24 kHz output, supports more than 15 Indian languages and is designed to maintain natural prosody, tone, emotion and pacing.
It claims to handle code-mixed speech, interruptions and overlapping dialogue with sub-second latency, which should make it suitable for real-time interactive applications such as government helplines, multilingual conversational agents and voice-driven workflows in healthcare, banking and logistics. Inya VoiceOS is currently released as a research preview ahead of a larger planned 14 billion-parameter version.
Soket AI: Pragna 1B
Soket AI development is designed to be transparent and open, with model weights and artefacts released under permissive licences to encourage research and community involvement. Its Pragna 1B LLM sports 1.25 billion parameters, with a context length of 2048 tokens. It is trained on 6.3 million English Wikipedia articles and additional Indic datasets for cultural contextualisation. The company has built its model on top of Meta’s Llama-2 base tokeniser and added six Indian languages. Open releases like this speed research, and they give engineers a base to fine-tune for regional tasks.
Soket AI’s Project EKA is an initiative to build large, open-source foundational models tailored to India’s linguistic and cultural diversity. The project outlines plans for foundation-based and instruction-tuned models with over 100 billion parameters, trained on curated Indian training datasets exceeding 2 trillion tokens and evaluated against India-specific benchmarks with global standards.
Dhi-5B
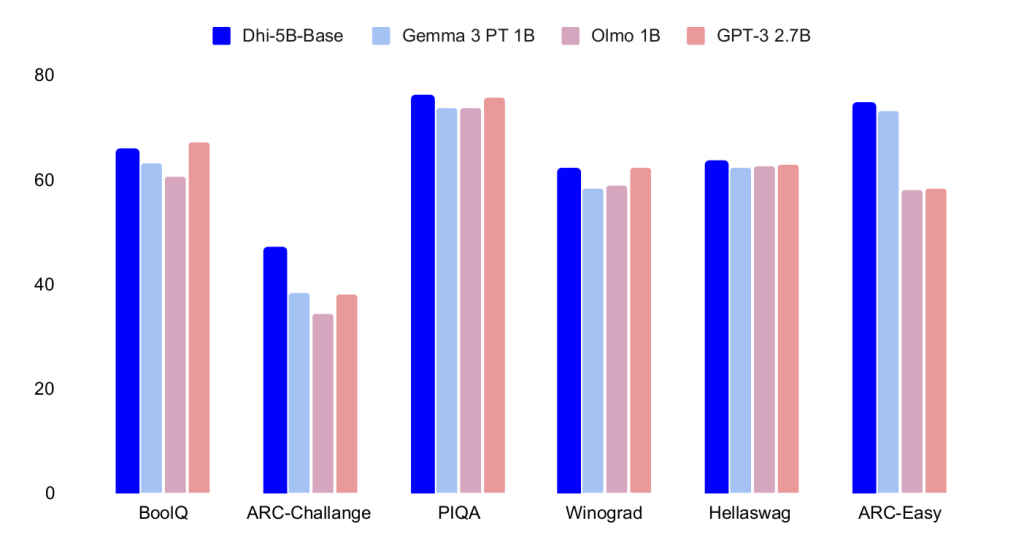
Dhi-5B (Base) is an independently developed multimodal language model created by an IIT Guwahati student/researcher with a mere budget of Rs 1 lakh. The core model is reported to have around 5 billion parameters and is optimised for efficiency. The training included core pre-training, context extension, supervised fine-tuning and vision extension, enabling the model to handle language understanding and potentially visual input.
Other companies in the race
Gan.AI and Avataar deliver media and agent tooling that leans on generative models. GenLoop and ZenteiQ pitch personalised LLM infrastructure and engineering-grade AI, respectively. Healthcare and research-focused firms such as IntelliHealth and Shodh AI aim to apply LLM techniques to domain datasets. Tech Mahindra’s Maker’s Lab represents larger corporate R&D labs testing generative AI for enterprise use. These players are pursuing different products and revenue paths while sharing the same underlying trend: commoditised modelling plus vertical specialisation.
Future outlook
Sovereign AI matters because a model trained and governed inside India can better handle Indian languages and dialects, understand the Indian context better, and be more assuring from a data quality and security standpoint.
Both public and private players are stepping up to research and build models like the ones mentioned before. But they will cost a lot, and investors want proven business models, not only model benchmarks.
Let’s expect incremental evolution, capable of solving local problems.
We are watching this market. Keep reading Digit.in to learn more about AI and other cutting-edge tech.
Also Read: GUVI AI breaks language barrier for inclusive tech at India AI Impact Summit