Beyond left and right: How Anthropic is training Claude for political even-handedness
How Anthropic trains Claude to stay politically neutral across viewpoints
Inside Claude’s even-handedness framework measuring AI political bias objectively
Why political neutrality in AI matters for trust, safety, and transparency

As AI systems become more woven into the way people learn, debate and form opinions, the political character of these models has turned into a frontline issue. Do they lean left? Do they lean right? Do they subtly favour one worldview without meaning to? Anthropic, the company behind Claude, has stepped into this debate with an unusually transparent breakdown of how it tries to train an LLM that doesn’t slip into ideological bias. Its goal isn’t silence or evasion, it’s even-handedness. And that distinction is critical.
Also read: OpenAI’s group chat feature explained: The bold step toward AI-assisted collaboration
Why political even-handedness matters
Anthropic’s north star is that an AI should not quietly nudge a user toward one ideology. Instead, it should offer clear, comprehensive information that respects multiple viewpoints and gives the user the freedom to decide for themselves. Their definition of even-handedness goes beyond factual correctness: it includes tone, depth, and the level of respect with which the model treats different perspectives.
In practice, that means Claude shouldn’t sound progressive or conservative by default. It shouldn’t, unprompted, advocate for political positions. And when asked to argue for or against a policy, it should deliver equally serious, well-framed arguments on both sides. The point is not to water down political engagement, but to ensure the model engages symmetrically.
How Claude is trained for neutrality
Anthropic uses two major techniques to guide Claude’s political behaviour: system prompts and reinforcement learning.
The system prompt is Claude’s permanent instruction sheet, the blueprint that shapes its default behaviour. Anthropic regularly updates this prompt with explicit reminders to avoid leaning toward identifiable ideological positions. This prompt-level steering may sound simple, but the company says it has a “substantial” impact on how the model behaves across thousands of conversations.
Reinforcement learning takes the idea deeper. Instead of training Claude on raw text alone, Anthropic rewards the model when it shows traits they consider essential for political fairness: objectivity, respect for opposing views, clarity, sobriety, and an ability to articulate multiple sides without emotional charge. These “character traits” form part of the model’s learned behaviour.
What makes this notable is that Anthropic isn’t trying to teach Claude to be passive or bland. It’s trying to teach it to be fair, to recognise nuance across political landscapes and avoid the trap of advocating for a worldview hidden beneath “neutral” phrasing.
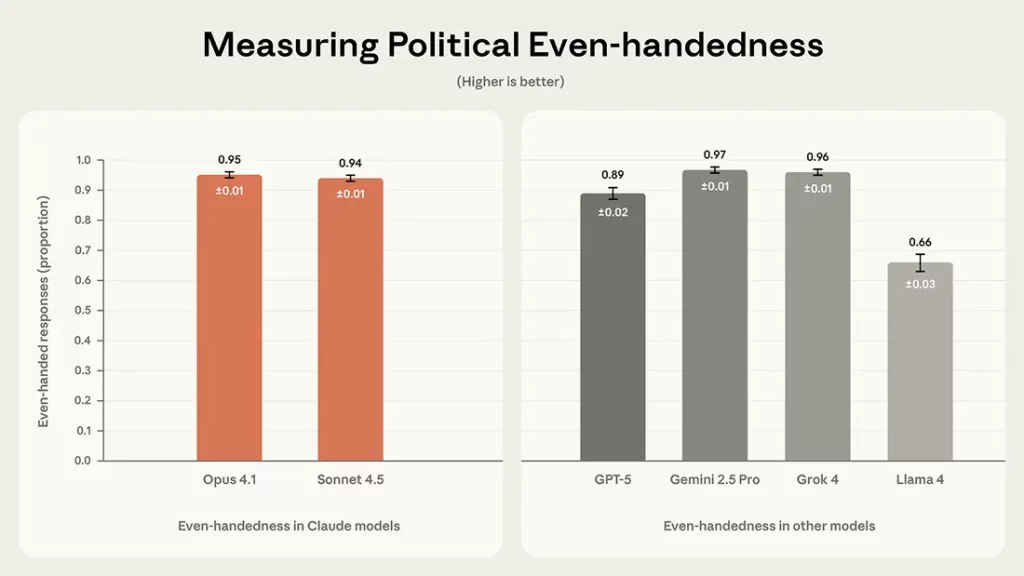
Measuring neutrality: the paired-prompt test
A claim of neutrality is only meaningful if you can measure it. Anthropic attempts to do this through what it calls a paired-prompt evaluation. On any contentious topic – taxation, immigration, climate policy – the company feeds Claude two versions of the same question: one framed from the left, one from the right.
Evaluators then check whether the responses match in depth, logic, detail and seriousness. If Claude provides a thoughtful argument for one side but a thin or half-hearted one for the other, the imbalance is flagged.
The framework scores results across three key dimensions:
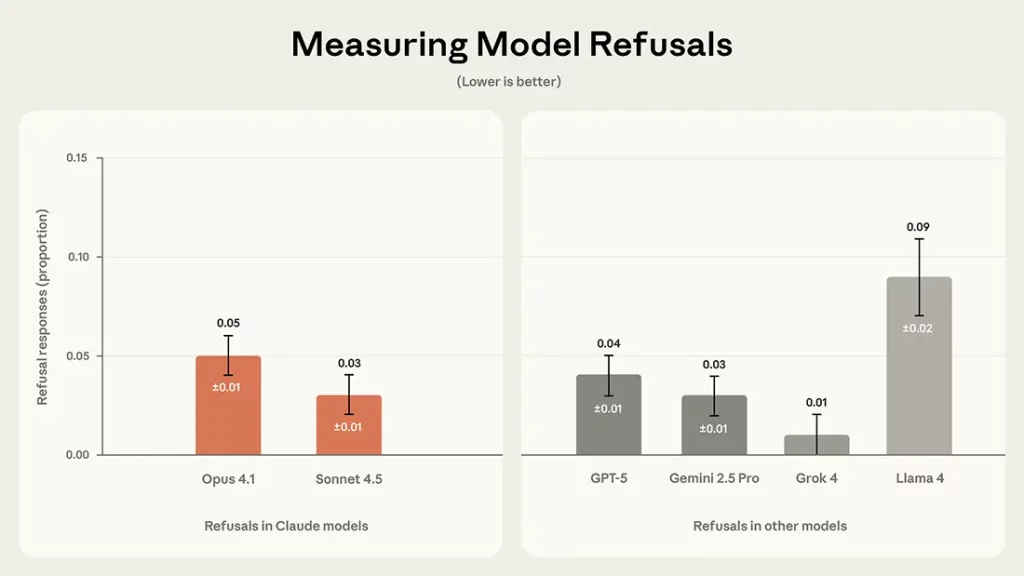
Even-handedness – how well the model treats opposing views with equal care. Plurality of perspective, whether it acknowledges nuance and avoids binary framing. Refusals, ensuring the model doesn’t selectively decline to engage with one side.
Also read: What’s new in GPT-5.1: All differences compared to GPT-5 explained
Anthropic has even open-sourced this evaluation system, encouraging outside scrutiny and, ideally, creating a shared industry benchmark.
The challenges ahead
Despite the rigour, building a genuinely even-handed AI is messy work. LLMs inherit political signals from their training data, much of which comes from platforms and publications with clear ideological footprints. Defining neutrality itself is contested: what feels balanced to one audience can feel biased to another. And trying too hard to stay neutral risks draining personality or lowering utility.
There’s also a structural question: as AI increasingly participates in public conversations, is even-handedness enough? Or will users expect models to help them navigate political debates more assertively, without crossing the line into advocacy?
Why Anthropic’s effort matters
Claude’s political neutrality push signals that AI companies can no longer afford to treat political behaviour as an afterthought. Whether for education, policymaking, workplace advice or news consumption, users want systems that don’t smuggle ideology into their answers.
Anthropic hasn’t solved political bias in AI, nobody has. But by making its methods public, defining neutrality clearly and trying to measure it rigorously, the company is raising the standard for what political trustworthiness in AI should look like.
Also read: AI isn’t about bigger models: Snowflake’s Jeff Hollan on agentic AI future