What is VaultGemma: World’s most privacy conscious AI LLM explained
Google DeepMind’s VaultGemma sets a new benchmark for privacy-first AI models
VaultGemma uses differential privacy to ensure no memorisation of sensitive training data
World’s most privacy-conscious LLM explained: how VaultGemma balances privacy and utility

Artificial intelligence has raced ahead in capability, but the question of privacy lingers like a shadow over every large language model (LLM). What happens when models memorise personal data from their training sets? How can developers assure users that their queries won’t resurface in some future output? In a bid to answer these pressing concerns, Google DeepMind has unveiled VaultGemma, a new family of models it calls the world’s most capable differentially private LLM.
VaultGemma represents more than just another entry in the Gemma series. It is the first large-scale attempt to train an open model from scratch with differential privacy at its core, a mathematical framework that limits the influence of any individual data point on the final model. In plain terms, it is a system built to learn without memorising, to generate without exposing.
Also read: Gemma 3n: Google’s open-weight AI model that brings on-device intelligence
How VaultGemma works
The breakthrough lies in the training method. VaultGemma uses a technique known as DP-SGD (differentially private stochastic gradient descent), where random noise is added to the training updates. This ensures that no single training sequence, defined as 1,024 consecutive tokens, can be uniquely identified or reproduced by the model.
The privacy guarantee is strict: VaultGemma achieves an epsilon of 2.0 with delta set to 1.1e-10. These figures may sound abstract, but they reflect a guarantee that the model’s outputs are nearly indistinguishable whether or not a specific sequence was present in the training data. That makes it almost impossible for malicious users to extract verbatim text or private details.
To make this feasible at scale, Google researchers developed new scaling laws for private training. These laws help determine the optimal balance between model size, training steps, and the amount of noise injected all under a fixed compute and privacy budget. Without this tuning, differentially private training would simply be too unstable and resource-intensive.
Performance vs. privacy
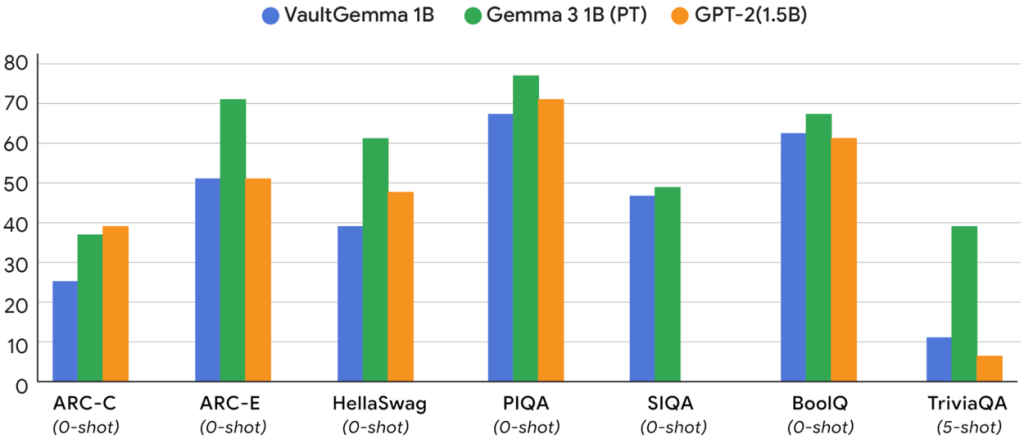
The big question is whether privacy compromises ability. VaultGemma, with around 1 billion parameters, performs surprisingly well across benchmark tests such as HellaSwag, PIQA, BoolQ, and TriviaQA. It does not yet rival state-of-the-art non-private LLMs, but it closes the gap with models from just a few years ago.
Also read: Sam Altman on AI morality, ethics and finding God in ChatGPT
Perhaps more importantly, it shows no detectable memorisation. When researchers attempted to feed VaultGemma partial snippets from its training data, the model failed to reproduce the original text, an intentional outcome, and one that underscores its privacy promise.
Still, trade-offs exist. Training with DP is costly in both compute and time. Models also tend to plateau earlier in performance compared to their non-private peers. For VaultGemma, the result is a capable but not cutting-edge assistant. Yet as privacy laws and user expectations tighten, the compromise may be worthwhile.
Why VaultGemma matters
The release of VaultGemma marks a turning point in how AI companies think about trust. Instead of retrofitting filters or relying solely on governance frameworks, Google is building privacy guarantees into the model’s architecture itself.
This shift could have far-reaching consequences. In areas such as healthcare, education, or financial services, domains where user data is deeply sensitive, VaultGemma-like systems could pave the way for responsible AI adoption. For researchers, the open release of the model and its training recipe provides a crucial testbed for exploring better private training methods.
It is also a subtle challenge to competitors. While most LLMs today, from OpenAI’s GPT to Anthropic’s Claude, are trained without differential privacy, VaultGemma positions itself as a glimpse into a future where privacy is not optional but foundational.
VaultGemma is not perfect. Its guarantees apply at the sequence level, not across entire user histories. Its utility is strong but not state-of-the-art. And the overhead of DP training still makes scaling to trillion-parameter models a formidable task.
Yet as the debate around AI safety, security, and compliance intensifies, VaultGemma’s debut feels timely. It demonstrates that high-quality language models and strong privacy protections are not mutually exclusive. The real test now is whether others in the AI industry follow suit or whether VaultGemma remains a pioneering, if solitary, experiment in making large language models more privacy conscious.
Also read: Are AI chatbots safe for children? Big tech companies need to answer, says US FTC