US Government report claims China 8 months behind: Is the AI lead real or a benchmark illusion?

The Center for AI Standards and Innovation (CAISI), an American government body, has compiled a report that shows China’s best AI model to be eight months behind major American frontier models. Sounds convenient, right? I’ve been looking at this evaluation of DeepSeek V4 Pro and the more I look, the more the 8 month headline feels like it may not entirely be true. I am not saying that the report is wrong but when one of the competitors is the one saying that they are in the lead, I feel that brings a question worth asking: who’s grading the test, and who designed the questions?
Also read: Understanding camera sensors: APS-C vs Full Frame – Which one do you actually need?
Who designed the questions?
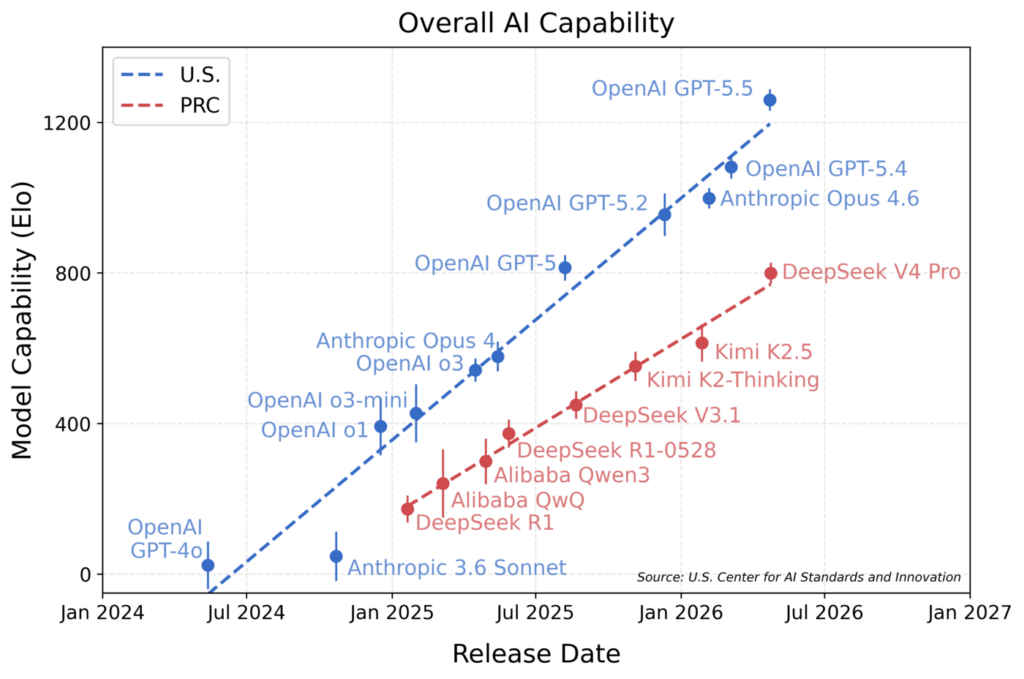
CAISI ran DeepSeek V4 Pro through benchmarks covering all the major sectors – cybersecurity, software engineering, abstract reasoning, and mathematics. Using a statistical method borrowed from psychometric testing, they placed it at roughly the same level as GPT-5 which launched about eight months before today’s American frontier. Hence the claim of it being 8 months behind.
The methodology is described in detail, confidence intervals are displayed, and CAISI pre-committed to its benchmark suite before seeing the results. That is more than most evaluators care to do. However, the benchmarks most damaging to DeepSeek’s performance – PortBench, CTF-Archive-Diamond, and ARC-AGI-2 semi-private – are all internally developed by CAISI or private data sets, where independent verification is impossible. You cannot verify an experiment that you cannot see.
Also read: Best 10,000mAh wireless power banks in India for iPhone and Android in 2026
According to DeepSeek, V4 Pro is rated on par with Opus 4.6 and GPT-5.4 – models that were released only two months ago, not eight. In addition, Artificial Analysis, an organization that provides AI capability evaluations independent of geopolitical interests, states that the gap between US and China remains steady, not increasing. When a US government organization develops proprietary tests, conducts them using a Chinese model, and declares that China is falling behind, there is no way to verify the claims. The figures may be accurate. But it is not a scientific method. That’s just a credentialed opinion.
The part everyone’s burying
In CAISI’s cost comparison, DeepSeek V4 Pro comes cheaper than GPT-5.4 mini on five out of seven tests, even more than 50% at times. Cursor, one of the more popular AI coding assistants, built its own model on a Chinese open-weight model precisely because it was cheaper than OpenAI and Anthropic. Capability tests test only one characteristic of a model. Cost per useful task dictates scalability. By that standard, the gap is far closer than eight months.
Is the lead real then? Yes and no. While the difference on ARC-AGI-2 tests – GPT-5.5 at 79% and DeepSeek at 46% – cannot be disregarded, “eight months behind” is an exact benchmark figure from internal comparisons done by one competitor against another.
The US likely has a real but contested capability lead. China is winning on economics. Calling it a race assumes both sides are optimising for the same thing when they might not be.
Also read: Vivo X300 FE early impressions: Promising Zeiss cameras but what about the price?