Claude is taking AI model welfare to amazing levels: Here’s how
Claude gets a nuclear safeguard, protecting AI from dangerous misuse and threats
Anthropic’s safeguard flags harmful nuclear queries with accuracy, zero false positives
Public-private partnership delivers Claude’s nuclear upgrade, setting AI safety standards worldwide

When people talk about “welfare,” they usually mean the systems designed to protect humans. But what if the same idea applied to artificial intelligence? For Anthropic, the company behind Claude, welfare means ensuring AI models operate safely, shielding them and society from harmful misuse.
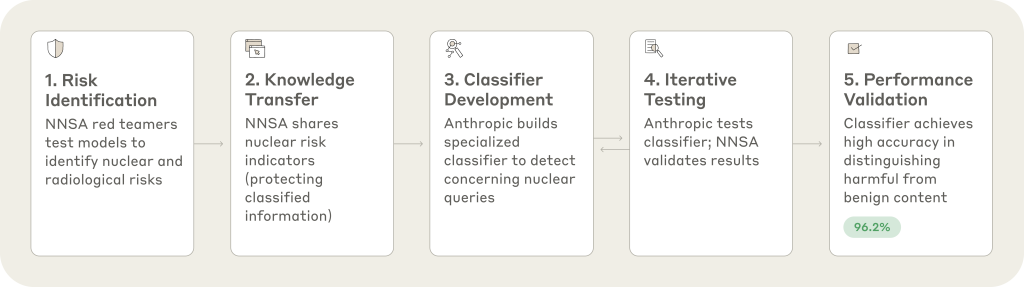
This month, Anthropic unveiled a breakthrough that pushes AI model welfare to new heights: a nuclear safeguards classifier. Built in partnership with the U.S. Department of Energy’s National Nuclear Security Administration (NNSA) and several national laboratories, this system is designed to detect and block potentially harmful nuclear-related prompts before they can spiral into misuse.
It’s a move that shows Anthropic isn’t just building powerful AI, it’s setting the standard for responsible AI governance.
Also read: Unlike ChatGPT or Gemini, Anthropic’s Claude will end harmful chats like a boss: Here’s how
Nuclear knowledge
The nuclear field embodies the paradox of dual use. Nuclear power can fuel cities and nuclear medicine can save lives, but the same knowledge can also enable weapons of mass destruction.
That tension is amplified in the age of AI. With models like Claude becoming more knowledgeable, experts worry they could be manipulated into providing sensitive details about weapons design or proliferation.
Anthropic’s safeguard aims to prevent that risk before it becomes reality.
How the safeguard works
The classifier screens nuclear-related queries in real time, distinguishing harmless curiosity from high-risk intent. A student asking Claude to explain nuclear fusion? Approved. A query probing centrifuge design? Blocked.
The system was shaped through red-teaming exercises, where experts tried to force Claude into unsafe responses. Insights from those tests were used to train the classifier, which has now achieved:
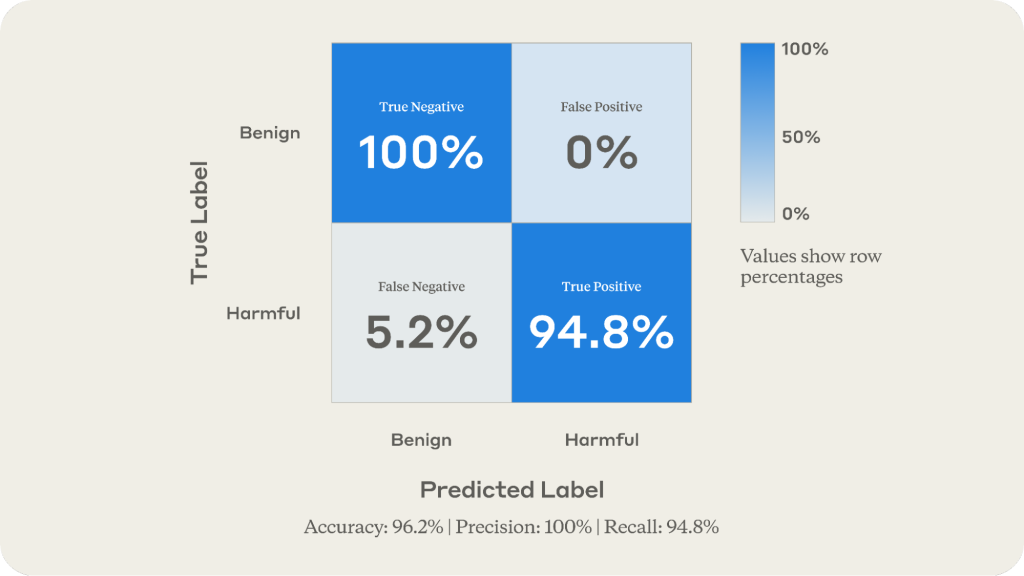
- 94.8% accuracy in catching harmful queries
- Zero false positives in testing, avoiding the mistake of blocking legitimate science discussions
- Promising results in early real-world deployment
The goal is not to censor nuclear knowledge but to ensure accessibility with safety.
Also read: Anthropic explains how AI learns what it wasn’t taught
What makes this breakthrough stand out isn’t just its accuracy but its approach. By partnering with government nuclear experts, Anthropic has shown how public–private collaboration can deliver credible safeguards for AI.
And the company isn’t keeping it to itself. Through the Frontier Model Forum, Anthropic plans to share its methods, encouraging other AI labs to adopt similar protections for domains like bioweapons, chemistry, and cybersecurity.
The nuclear safeguard becomes more than just a feature, it’s a blueprint for future AI safety.
Why it matters now
As AI systems grow smarter, the risks tied to dual-use knowledge grow as well. Governments are drafting regulations, but technical guardrails like this are what make safety real. Anthropic’s move shows how proactive design can complement policy to prevent catastrophic misuse.
It also reinforces the company’s safety-first reputation. From its “constitutional AI” training methods to this safeguard, Anthropic is consistently emphasizing responsibility as much as intelligence.
So what does “AI model welfare” mean in practice? It means creating the digital equivalent of seatbelts, guardrails that allow AI to function at scale without exposing society to unacceptable risks.
By giving Claude a nuclear safeguard, Anthropic hasn’t upgraded its intelligence. It’s upgraded its resilience. And in the long run, that may matter even more.
Because as AI becomes central to classrooms, research labs, and decision-making systems, its welfare, its safeguards, its protections, must be treated as seriously as its capabilities.
Claude’s so-called “nuclear upgrade” is a reminder that in the race to build smarter AI, the real victory may come from building safer AI.
Also read: Fair use vs copyright: Anthropic’s case and its impact on AI training