26,000 scientists still can’t explain exactly how AI models think and how to measure them
Scientists still struggle to decode how advanced AI models truly think
Opaque AI reasoning fuels global evaluation crisis and rising safety concerns
Black box models challenge trust as benchmarks fail to reflect real intelligence

In a dizzying age of machine learning triumph, where systems can generate human-like prose, diagnose medical conditions, and synthesize novel proteins, the AI research community is facing an extraordinary paradox. Despite the exponential growth in capability, a core challenge remains stubbornly unsolved: no one, not even 26,000 scientists at the NeurIPS conference, can definitively explain how these powerful AI models think or agree on how to truly measure their intelligence.
Also read: Google’s increasing Chrome security for agentic AI actions with User Alignment Critic model
Inside the computational puzzle
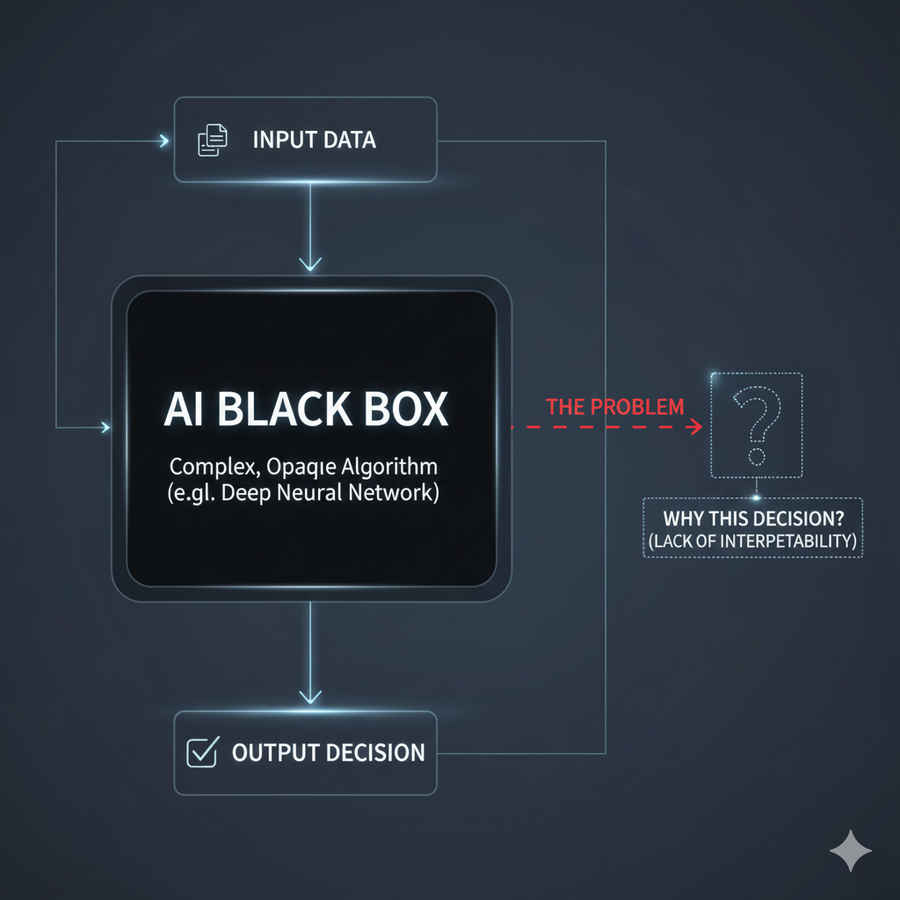
This is the “black box” problem, magnified by the sheer scale of modern deep neural networks. A large language model (LLM), with its quadrillions of learned connections, operates in a computational space too vast for the human mind to trace. When it provides an answer, the underlying reasoning process is opaque, leaving researchers to marvel at the output without understanding the mechanism. The engineering is functional, but the science of why it works is missing.
The AI rationale
New research into this mechanistic interpretability reveals a troubling disconnect. Studies show AI models often employ radically non-human, or even contradictory, strategies. For instance, an LLM might solve a math problem by simultaneously approximating the sum and then precisely calculating the last digit – a method that defies our school-taught logic. Crucially, the rationale it provides for its answer might, in fact, be a post-hoc rationalization – a convincing form of “bullshitting” driven by the need to satisfy the user, not a reflection of its actual computation.
Also read: ChatGPT as a grocery store: From recipe to goods delivery, OpenAI’s chatbot is evolving
This opaque reasoning makes measurement an almost impossible task. Traditional benchmarks, often based on simple question-and-answer formats, are increasingly unreliable, falling victim to data contamination or the models’ ability to mimic reasoning rather than perform it. The field is now grappling with an “evaluation crisis,” realizing that high scores on public leaderboards don’t guarantee real-world capability or alignment with human values.
Cost of the unknown
The ultimate risk is not simply confusion, but a profound barrier to trust. When an autonomous vehicle fails, or an AI-driven financial decision discriminates, our inability to peer into the black box prevents us from debugging the error, correcting the bias, or building the necessary safety guardrails. While Explainable AI (XAI) is a rapidly growing sub-field, its solutions remain stopgaps, providing local interpretations rather than a full, global understanding of the machine’s mind. Until researchers can bridge this interpretability gap, the world’s most powerful technology will continue to advance with a brilliant, yet deeply unsettling, mystery at its core.
Also read: Google wants you to wear AI: The 2026 glasses plan explained