Maia 200 explained: Microsoft’s custom chip for AI acceleration
Microsoft Maia 200 boosts AI inference efficiency in Azure centers
Maia 200 is Microsoft’s custom chip built for AI inference
Custom AI accelerators like Maia 200 reduce cloud inference costs

As artificial intelligence shifts from experimental demos to everyday products, the real pressure point is no longer training models but running them at scale. Every AI search result, chatbot reply, or copilot suggestion relies on inference, the stage where a trained model produces answers in real time. To meet this demand, Microsoft has introduced Maia 200, a custom AI accelerator purpose built for inference inside Azure data centers.
Maia 200 is not designed to replace general purpose GPUs across the board. Instead, it reflects a more focused philosophy. Microsoft is optimizing for the workloads that matter most to its cloud business today: serving large language models efficiently, reliably, and at massive scale. The result is a chip that prioritizes throughput, memory efficiency, and cost per query over headline grabbing training benchmarks.
Also read: US vs China AI development: Mistral calls it a “fairy tale,” Google sees 6-Month lead
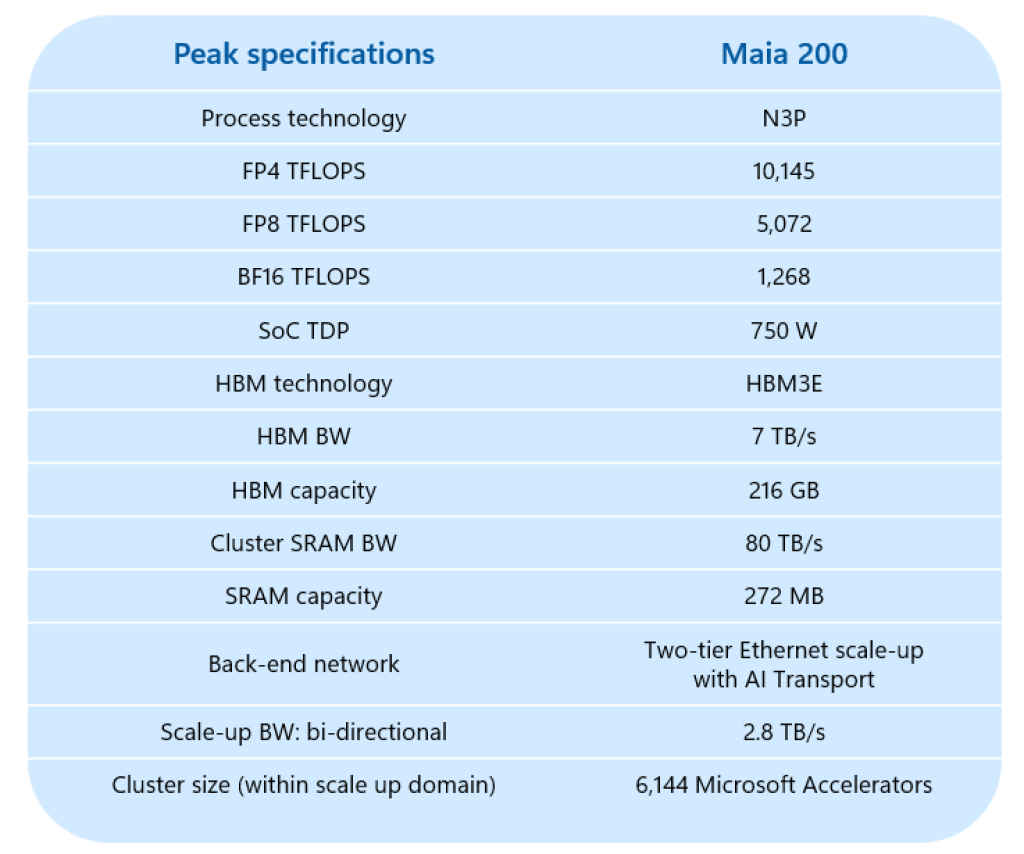
Built for inference at cloud scale
The defining characteristic of Maia 200 is its emphasis on low precision computing. During inference, models can often operate at lower numerical precision without sacrificing output quality. Maia 200 takes advantage of this by supporting formats like FP4 and FP8, allowing it to process more operations per second while consuming less power. This makes the chip especially well suited for AI services that must respond instantly to millions of users.
Memory architecture plays an equally critical role. Maia 200 pairs its compute units with a large pool of high bandwidth memory, enabling large models or substantial model shards to sit close to the processor. This reduces latency and avoids the performance penalties that come from constantly fetching data from slower memory tiers. A sizeable on-chip SRAM further accelerates frequently accessed data, keeping the compute pipelines busy.
Data movement has clearly been treated as a first class design concern. Dedicated engines manage how data flows between memory, compute units, and the network. In large deployments, Maia 200 connects through a high bandwidth Ethernet-based interconnect that allows thousands of chips to operate as a single logical system. This is essential for serving today’s largest models, which often need to be distributed across multiple accelerators.
Why Maia 200 matters to Microsoft’s AI strategy
Beyond the technical details, Maia 200 is significant because of what it says about Microsoft’s long term AI ambitions. For years, cloud providers depended almost entirely on third party accelerators. While those chips remain central to Azure, Maia 200 signals a shift toward tighter vertical integration. By designing its own silicon, Microsoft can optimize hardware, system design, and software together around real production workloads.
Software support is a key part of this equation. Maia 200 is designed to work with established frameworks such as PyTorch, minimizing friction for developers. Custom compilers and optimization tools handle the heavy lifting behind the scenes, translating models into forms that run efficiently on the hardware. For most users, the goal is that Maia 200 simply feels like faster and cheaper AI, without requiring code rewrites.
The economic implications are substantial. Inference costs dominate the operating expenses of large scale AI services. Even modest gains in performance per watt or performance per dollar can translate into massive savings when multiplied across billions of requests. Microsoft says Maia 200 delivers a meaningful improvement in efficiency compared to earlier infrastructure, helping make AI services more sustainable and scalable.
Maia 200 is not about winning benchmark battles or replacing GPUs outright. It represents specialization. As AI infrastructure matures, different chips are emerging for different roles. Training, inference, and edge deployment each have distinct requirements. Maia 200 is Microsoft’s answer to the inference problem, quietly powering the AI experiences that are becoming part of everyday digital life.
Also read: Jensen Huang: AI will create wealth for plumbers, builders, factory workers, here’s how