AMD Instinct MI350: A deep dive into Team Red’s AI powerhouse

The AI accelerator landscape is undergoing one of its most competitive phases in years. AMD’s newly announced Instinct MI350 series arrives as a bold response to NVIDIA’s Blackwell architecture and the growing computational demands of generative AI and large-scale language models. With 185 billion transistors, support for up to 288 GB of HBM3E memory, and the new CDNA 4 architecture, AMD has made it clear that it’s ready to compete toe-to-toe in the data centre.

Compared to the MI325, the MI350 is a full architectural rethink. The CDNA 4 architecture introduces a chiplet-based approach with an emphasis on low-precision AI workloads, high bandwidth memory, and improved scalability. In a market increasingly defined by large model sizes and inference efficiency, AMD’s design philosophy is finally aligned with the future of AI.
CDNA 4 architecture: The heart of MI350
CDNA 4 represents a significant evolution from CDNA 3, which debuted with the MI300X. While the previous generation made strides in compute density and mixed-precision performance, CDNA 4 focuses sharply on the needs of modern AI. Central to the MI350X is a new 3D chiplet design that stacks eight compute dies, referred to as XCDs, on top of just two I/O dies, or IODs. This is a departure from the four-IOD layout in the MI300 series.

Reducing the number of IODs is more than a simplification. It shortens the physical distance data must travel, decreasing latency and increasing power efficiency. The streamlined topology is particularly beneficial for workloads where every microsecond matters, such as training transformer-based language models.
The XCDs are built on TSMC’s N3P process node, and the IODs use the more mature 6nm process. This pairing reflects a strategy that balances leading-edge performance with manufacturability and cost. Architecturally, CDNA 4 also includes revamped compute units optimised for low-precision types like FP4 and FP6, positioning MI350 well for both training and inference on large models.
Chiplet and packaging innovations
AMD’s prowess in chiplet design comes into full focus with the MI350X. The company continues to lean into advanced packaging techniques like CoWoS-S (Chip-on-Wafer-on-Substrate – Stacked) and SoIC (System on Integrated Chip), enabling vertical stacking of the XCDs directly atop the IODs. This high-density stacking helps deliver more compute in a smaller footprint while improving interconnect bandwidth between the compute and I/O layers.

The MI350X integrates eight XCDs, each with 32 compute units, alongside eight HBM3E memory stacks and a 256 MB Infinity Cache. The choice to use TSMC’s N3P for the compute dies allows for increased transistor density, while the 6nm IODs handle memory control, I/O functions, and chip-to-chip communication. The combined architecture supports higher yields and thermal efficiency compared to a monolithic die of the same scale.
More than performance, this approach reflects a shift in data centre GPU design where modularity, stacking, and heterogeneous integration are critical for scalability and manufacturing viability.
Compute Engine and core configuration
Each XCD in the MI350X houses 32 compute units, resulting in a total of 256 CUs across the chip. This makes the MI350X one of AMD’s most compute-dense accelerators to date. But it’s not just about raw numbers. The compute units have been redesigned for better AI throughput, particularly for matrix-heavy operations essential in machine learning.

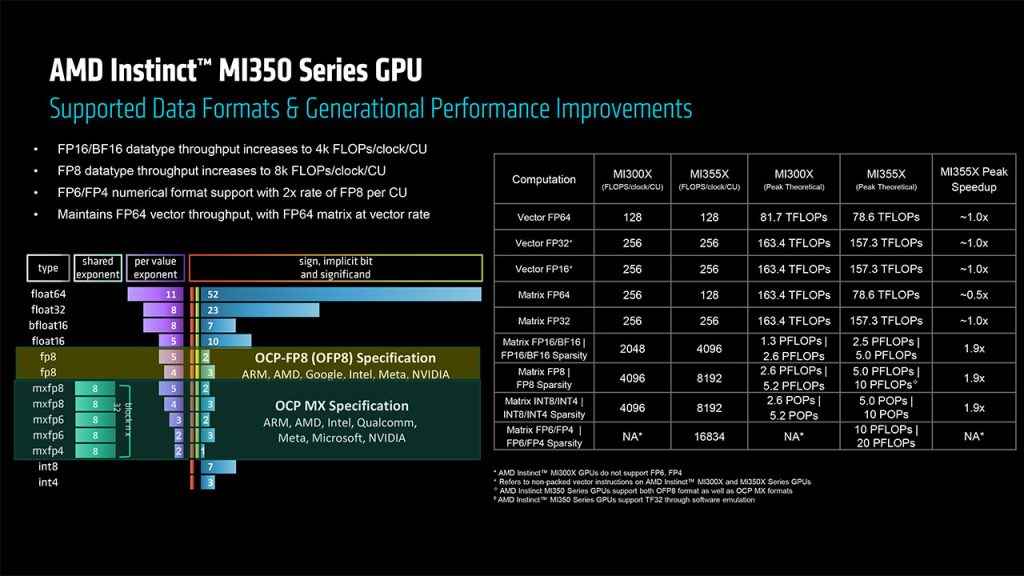
Support for ultra-low precision formats such as FP6 and FP4 is a defining feature of this generation. These datatypes are especially valuable in generative AI models, where memory pressure and throughput constraints are constant challenges. The inclusion of these formats enables MI350 to perform more operations per second while keeping energy and bandwidth demands in check.
Changes to the SIMD lanes, vector pipelines, and matrix cores ensure that each CU is better aligned with the needs of AI, while still retaining capabilities for traditional HPC tasks like FP64 simulations. This dual-use flexibility allows MI350 to be deployed in both AI and scientific computing contexts without compromise.
Memory subsystem: HBM3E and Infinity Cache
AMD has equipped the MI350X with an enormous 288 GB of HBM3E memory, spread across eight stacks. This configuration delivers a total bandwidth of up to 8 terabytes per second, one of the highest in the industry today. Such high memory capacity and throughput allow the MI350X to run massive language models, including those with up to 520 billion parameters, without the need to split them across multiple GPUs.

Beyond raw capacity, AMD includes 256 MB of Infinity Cache in the MI350X. This L3-style cache sits between the compute dies and HBM, reducing the number of accesses to external memory and thereby improving effective bandwidth and lowering latency. The net result is better performance per watt, which is critical as workloads scale and inference demands become more complex.
In comparison, NVIDIA’s GB200 platform uses a dual-chip approach with 192 GB of HBM3E per GPU, meaning AMD holds an advantage in model capacity per GPU, even though NVIDIA’s chip-to-chip bandwidth is very competitive.
Interconnects and system integration
The MI350 series also introduces improvements in system-level interconnects. The 4th Gen Infinity Fabric offers fast and low-latency communication between components, with a massive 5.5 terabytes per second of bandwidth linking the two IODs. This internal bandwidth allows for seamless data sharing between compute clusters within the GPU package.
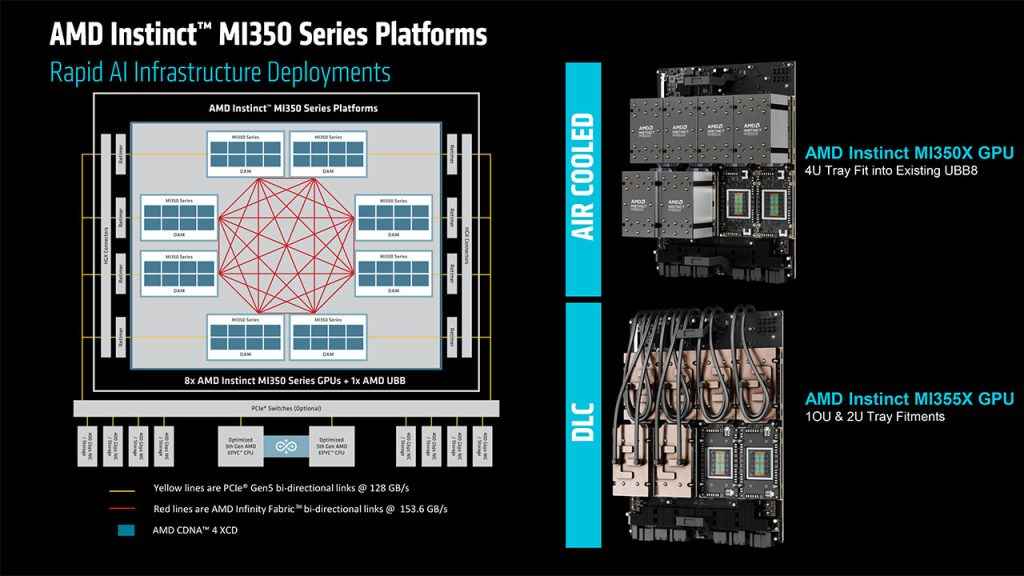
For deployment at scale, AMD supports the Open Compute Project’s UBB8 standard, enabling up to eight MI350 GPUs per server node. When liquid cooling is deployed, data centres can scale up to 128 GPUs per rack which is ideal for hyperscalers and AI training labs that need dense compute per square foot.
Moreover, the MI350 integrates tightly with AMD’s EPYC CPUs and Pensando Pollara DPUs, enabling full-rack infrastructure solutions that are optimised for AI. This holistic design philosophy positions AMD not just as a chip vendor but as a complete platform provider.
Performance and efficiency claims
AMD claims that the MI350X delivers over three times the FP4 and FP6 performance of the MI300X. For full-precision FP64, performance remains strong, making the chip suitable for both AI and HPC. Perhaps more importantly, AMD points to a notable improvement in power efficiency and cost-per-token for inference workloads. These are two metrics that are top-of-mind for large-scale AI deployment.
The MI350X is rated for 1000 watts in air-cooled configurations, while the liquid-cooled MI355X pushes that to 1400 watts. These thermal profiles are in line with NVIDIA’s highest-end GPUs, reflecting the reality that modern AI accelerators are power-hungry by design. Still, AMD appears to have managed power delivery and thermal density effectively, thanks to its 3D stacking and improved heat dissipation paths.
Training performance for large transformer models sees significant gains, while inference benchmarks suggest that the MI350X can serve tokens more cheaply and quickly than NVIDIA’s B200 in several cases. If these claims hold up under independent testing, AMD could become a preferred vendor for inference-heavy workloads.
Software Ecosystem: ROCm 7 and developer support
No GPU story is complete without software, and here AMD has made significant progress. ROCm 7, the latest version of its AI software stack, includes enhanced support for PyTorch, TensorFlow, JAX, and ONNX. Day-zero support for frontier models like Llama 3, Mixtral, and Command-R+ ensures that developers can begin building immediately.
AMD has also opened up its APIs for mixed-precision quantisation, structured sparsity, and asynchronous compute pipelines. These additions bring ROCm closer in feature parity to NVIDIA’s CUDA and cuDNN libraries.
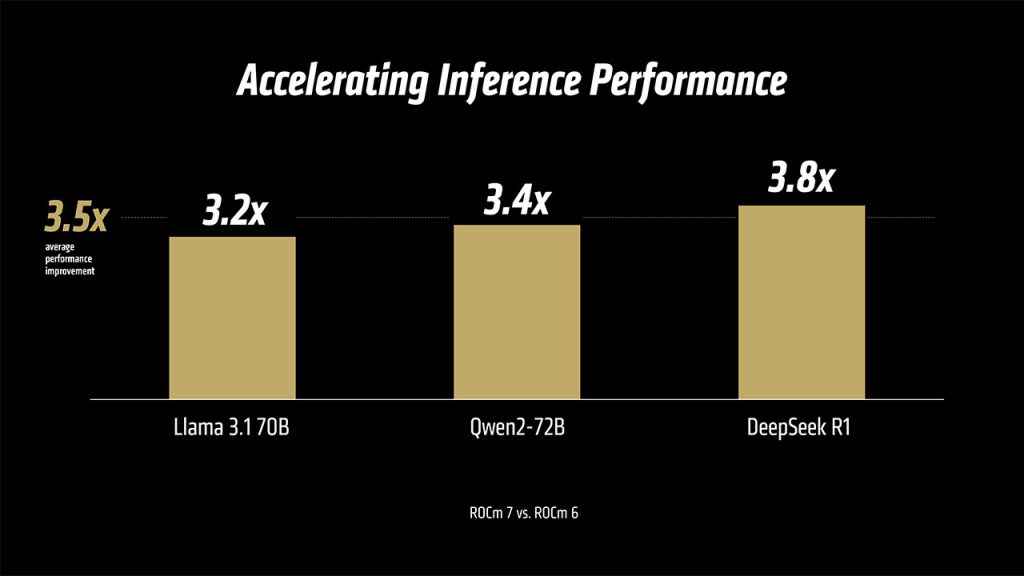
The AMD Developer Cloud offers developers access to MI300 and MI350 hardware for benchmarking and model development. In combination with strategic partnerships with Meta, Microsoft, and other AI-first companies, AMD is investing heavily in creating a viable alternative to CUDA’s software dominance. To know more about how far ROCm 7 has come, check out our deep dive on ROCm updates.
Deployment scenarios and use cases
The MI350X and MI355X are designed for varied deployment scenarios. Air-cooled systems are likely to find homes in enterprise racks, edge clusters, and academic HPC labs. Liquid-cooled variants will dominate hyperscale and training-centric deployments where power budgets are higher and infrastructure is custom-built for AI.
These GPUs are well suited for training large foundation models, performing real-time inference for generative AI applications, and running multi-tenant AI workloads in cloud environments. They also retain strong FP64 performance, making them viable for molecular dynamics, climate modelling, and other compute-intensive scientific simulations.
OEMs such as Supermicro, Lenovo, and HPE are already integrating MI350 GPUs into next-generation server designs, signalling a broad interest in AMD’s latest hardware.
MI350 vs GB200: Competitive analysis
In direct comparison with NVIDIA’s B200 and GB200, AMD’s MI350 series scores several wins on paper. It offers greater memory capacity per GPU, higher memory bandwidth, and support for newer AI formats like FP4 and FP6. These capabilities position AMD strongly in a segment that values speed and memory efficiency above all else.
However, NVIDIA still maintains an edge in software ecosystem maturity and model support out of the box. Its NVLink-based interconnects and Grace Hopper co-packaging offer tight integration that may appeal to users with highly tuned CUDA pipelines. Certain analysts argue that NVIDIA’s NVL72 rack scale system when viewed from the scale-up domain constitutes 72 GB200 GPUs whereas the MI355X rack scale systems are only 8 GPUs. So in certain workloads, the NVIDIA rack scale system has a tremendous lead over the AMD solution.
Yet, AMD’s advantage lies in its use of standardised platforms, better rack-level thermal design, and a more open developer model. This openness could prove persuasive to cloud vendors and enterprises wary of being locked into one ecosystem.
The battle continues
The AMD Instinct MI350 series is more than just a response to Blackwell, it’s a marker that AMD is fully in the game when it comes to AI infrastructure. Through innovations in chiplet architecture, memory bandwidth, and packaging, the MI350 delivers a compelling blend of performance, capacity, and scalability. That said, NVIDIA’s B300 chips are right around the corner and they’re already better in quite a few domains.

This launch marks a turning point. AMD is no longer chasing; it’s competing on equal terms with the market leader. With CDNA 4, ROCm 7, and full-rack solutions that integrate CPU, GPU, and DPU, AMD has evolved into a serious player in the AI space.
And this is only the beginning. With MI400, codenamed Helios, already on the roadmap for 2026 and beyond, AMD’s ambitions stretch further than this generation. If MI350 is a foundation, Helios might just be the leap that changes the landscape.