Data Science is an Ocean of Information—Stay Focused!

A primer on how to become a data scientist
How do I become a good data scientist? Should I learn R* or Python*? Or both? Do I need to get a PhD? Do I need to take tons of math classes? What soft skills do I need to become successful? What about project management experience? What skills are transferable? Where do I start?

Data science is a popular topic in the tech world today. It is the science that powers many of the trends in this world, from machine learning to artificial intelligence.
In this article, we discuss our teachings about data science in a series of steps so that any product manager or business manager interested in exploring this science will be able take their first step toward becoming a data scientist or at least develop a deeper understanding of this science.

Step 1: Define a Problem Statement
We all have heard conversations that go sometime like this: "Look at the data and tell me what you find." This approach may work when the volume of data is small, structured, and limited. But when we are dealing with gigabytes or terabytes of data, it can lead to an endless, daunting detective hunt, which provides no answers because there were no questions to begin with.
As powerful as science is, it's not magic. Inventions in any field of science solve a problem. Similarly, the first step in using data science is to define a problem statement, a hypothesis to be validated, or a question to be answered. It may also focus on a trend to be discovered, an estimate, a prediction to be made, and so on.
For example, take MyFitnessPal*, which is a mobile app for monitoring health and fitness. A few of my friends and I downloaded it about a year ago, and then used it almost daily for a while. But over the past 6 months, most of us have completely stopped using it. If I were a product manager for MyFitnessPal, a problem I might want to solve would be: how can we drive customer engagement and retention for the app?
Step 2: Get the Data
Today's data scientists access data from several sources. This data may be structured or unstructured. The raw data that we often get is unstructured and/or dirty data, which needs to be cleaned and structured before it can be used for analysis. Most of the common sources of data now offer connectors to import the raw data in R or Python.
Common data sources include the following:
- Databases
- CSV files
- Social media feeds like Twitter, Facebook, and so one (unstructured)
- JSON
- Web-scraping data (unstructured)
- Web analytics
- Sensor data driven by the Internet of Things
- Hadoop*
- Spark*
- Customer interview data
- Excel* analysis
- Academic documents
- Government research documents and libraries like www.data.gov
- Financial data; for example, from Yahoo Finance*
In the data science world, common vocabulary includes:
- Observations or examples. These can be thought of as horizontal database records from a typical database.
- Variables, signals, characteristics. These equate to the fields or columns in the database world. A variable could be qualitative or quantitative.
Step 3: Cleaning the Data
Several terms are used to refer to data cleaning, such as data munging, data preprocessing, data transformation, and data wrangling. These terms all refer to the process of preparing the raw data to be used for data analysis.
As much as 70–80 percent of the efforts in a data science analysis involve data cleansing.
A data scientist analyzes each variable in the data to evaluate whether it is worthy of being a feature in the model. If including the variable increases the model's predictive power, it is considered a predictor for the model. Such a variable is then considered a feature, and together all the features create a feature vector for the model. This analysis is called feature engineering.
Sometimes a variable may need to be cleaned or transformed to be used as a feature in the model. To do that we write scripts, which are also referred to as munging scripts. Scripts can perform a range of functions like:
- Rename a variable (which helps with readability and code sharing)
- Transform text (if "variable = "big" set variable = "HUGE")
- Truncate data
- Create new variables or transpose data (for example, given the birth date, calculate age)
- Supplement existing data with additional data (for example, given the zip code, get the city and state)
- Convert discrete numerical variables into a continuous range (for example: salary-to-salary range; age-to-age range)
- Date and time conversions
- Convert a categorical variable into multiple binary variables. For example, a categorical variable for region (with possible values being east, west, north, and south) could be converted into four binary variables, east, west, north, and south, with only one of them being true for an observation. This approach helps create easier joins in the data.
Sometimes the data has numerical values that vary in magnitude, making it difficult to visualize the information. We can resolve this issue using feature scaling. For example,consider the square footage and number of rooms in a house. If we normalize the square footage of a house by making it a similar magnitude as the number of bedrooms, our analysis becomes easier.
A series of scripts are applied to the data in an iterative manner until we get data that is clean enough for analysis. To get a continuous supply of data for analysis, the series of data munging scripts need to be rerun on the new raw data. Data pipeline is the term given to this series of processing steps applied to raw data to make it analysis ready.
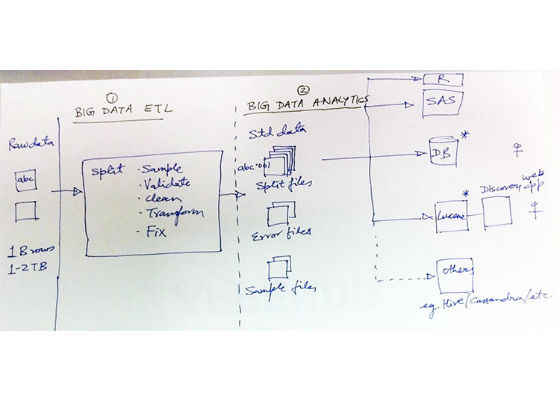
Step 4: Data Analysis and Model Selection
Now we have clean data and we are ready for analysis. Our next goal is to become familiar with the data using statistical modeling, visualizations, discovery-oriented data analysis, and so on.
For simple problems, we can use simple statistical analysis using the mean, medium, mode, min, max, average, range, quartile, and so on.
Supervised Learning
We could also use supervised learning with data sets that gives us access to actual values of response variables (dependent variables) for a given set of feature variables (independent variables). For example, we could find trends based on the tenure, seniority, and title for employees who have left the company (resigned=true) from actual data, and then use those trends to predict whether other employees will resign too. Or we could use historic data to correlate a trend between the number of visitors (an independent variable or a predictor) and revenue generated (a dependent variable or response variable). This correlation could then be used to predict future revenue for the site based on the number of visitors.
The key requirement for supervised learning is the availability of ACTUAL Values and a clear question that needs to be answered. For example: Will this employee leave? How much revenue can we expect? Data scientists often refer to this as "Response variable is labeled for existing data."
Regression is a common tool used for supervised learning. A one-factor regression uses one variable; a multifactor regression uses many variables.
Linear regression assumes that the unknown relation between the factor and the response variable is a linear relation Y = a + bx, where b is the coefficient of x.
A part of the existing data is used as training data to calculate the value of this coefficient. Data scientists often use 60 percent, 80 percent, or at times 90 percent of the data for training. Once the value of the coefficient is calculated for the trained model, it is tested with the remaining data also referred to as thetest data to predict thevalue of the response variable. The difference between the predicted response value and the actual value is the Holy Grail of metrics referred to as the test error metric.
Our quest in data science modeling is to minimize the test error metrics in order to increase the predictive power of the model by:
- Selecting effective factor variables
- Writing efficient data munging scripts
- Selecting the appropriate statistical algorithms
- Selecting the required amount of test and training data
Unsupervised Learning
Unsupervised learning is applied when we are trying to learn the structure of the underlying data itself. There is NO RESPONSE VARIABLE. Data sets are unlabeled and pre-existing insights are unclear. We are not clear about anything ahead of time so we are not trying to predict anything!
This technique is effective for exploratory analysis and can be used to answer questions like
- Grouping. How many types of customer segments do we have?
- Anomaly detection. Is this normal?
Analysis of variance (ANOVA) is a common technique used to compare the means of two or more groups. It's named ANOVA though since the "estimates of variance" is the main intermediate statistics calculated. The means of various groups are compared using various distance metrics, Euclidean distance being a popular one.
ANOVA is used to organize observations into similar groups, called clusters. The observations can beclassified into these clusters based on their respective predictors.
http://www.statsdirect.com/help/content/analysis_of_variance/anova.htm
Two common clustering applications are:
- Hierarchical clustering. A bottom-up approach. We start with individual observations and merge them with the closest one. We then calculate the means of these grouped observations and merge the groups with the means closest to each other. This is repeated until larger groups are formed. The distance metrics is defined ahead of time. This technique is complex and not advisable with a high-dimension data set.
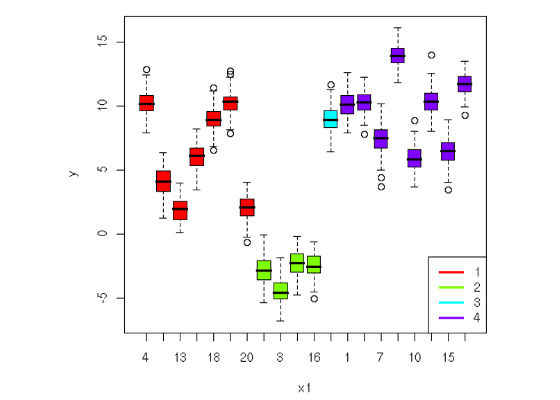
- K-means clustering. Uses a partitioning approach.
- We assume that the data has a fixed number of clusters in advance based on our intuition.
- We also assume the starting center for each cluster.
- Each observation is then assigned to the cluster with the mean closest to the observation
- The step is repeated until all observations have been assigned to a cluster.
- Now we recalculate the mean for the clusters based on the average of all the observations assigned to the cluster.
- Observations are reclassified to these new cluster and steps c, d, and e are repeated until they reach a stable state.
If a stable state is not achieved, we may need to refine the number of clusters (i.e., K) we assumed in the beginning or use a different distance metrics.
Step 5: Visualize and Communicate Effectively
The final clusters can be visualized for easy communication using tools like Tableau* or graphing libraries.
Tips from Data Science Practitioners
In my quest to understand data science, I met with practitioners working in companies, including Facebook, eBay, LinkedIn, Uber, and some consulting firms, that are effectively leveraging the power of data. Here are some powerful words of advice I received:
- Know your data. It's important to fully understand the data and the assumptions behind it. Otherwise, the data may be ineffectively used, which may lead to arriving at the wrong answer, solving the wrong problem, or both.
- Understand the domain and the problem. The data scientist must have a deep understanding of the business domain and the problem to be solved to be able to extract the appropriate insights from the data.
- Ethics. Don't compromise data quality to fit a hypothesis. The problem often is not ignorance, but our preconceived notions!
- It's a myth that a larger data set always offers better insights. Although an increased amount of data becomes statistically significant, a large data set also comes with higher noise. It's common to see the R-squared of a larger data set that is smaller than that of a smaller data set.
- While data science is not a product by itself, it can power brilliant products that solve complex problems. Product managers and data scientists that communicate effectively can become strong partners:
- The product manager initially brings to the conversation the business problem to be solved, questions to be answered, and constraints to be discovered and/or defined.
- The data scientist, who brings deep expertise in machine learning and mathematics, focuses on the theoretical aspects of the business problem. Modern data sets are used to perform data analysis, transformations, model selections, and validations to establish thefoundations of the theory to be applied to the business problem.
- The software engineer works to operationalize the theory and the solution. He or she needs a strong understanding of the mechanics of machine learning (Hadoop clusters, data storage hardware, writing production code, and so on).
- Learn a programming language. Python is easiest to learn; R is considered the most powerful.
Commonly Used Data Science Tools
R
R is a favorite tool of many data scientists and holds a special place in the world of academia, where data science problems are worked on from a mathematician's and statistician's perspective. R is an open source and rich language, with about 9,000 additional packages available. The tool used to program in R is called R Studio*. R has a steep learning curve, though its footprint is steadily increasing in enterprise world and owes some of it popularity to the rich and powerful Regular Expression-based algorithms already available.
Python
Python is slowly becoming the most extensively used language in the data science community. Like R, it is also an open source language and is used primarily by software engineers who view data science as a tool to solve real customer-facing business problems using data. Python is easier to learn than R, because the language emphasizes readability and productivity. It is also more flexible and simpler.
SQL
SQL is the basic language used to interact with databases and is required for all tools.
Other Tools
- Apache Spark offer Scala*
- MATLAB* is a mathematical environment that academia has used for a long time. It offers an open source version called Octave*
- Java* is used for Hadoop environments
What about the Soft Skills?
Below is a list of important soft skills to have, many of which you might already have in your portfolio.
- Communication. A data scientist doesn't sit in a cube and code Python programs. The data science process requires that you mingle with your team. You need to connect and build rapport with executives, product owners, product managers, developers, big data engineers, NoSQL* experts, and more. Your goal is to understand what they are trying to build and how data science and machine learning can help.
- Coaching. As a data scientist, your coaching skills will shine. You are not an individual contributor of the company; you are the CEO's best friend, who can help him or her shape the company—the product and the territory based on data science. For example, based on your data science results, you give perspective analysis results to the executive team recommending that the company launch dark-green shoes in Brazil; the same product will fail in Silicon Valley in the United States. Your findings can save millions of dollars for the company.
- Storyteller. A good data scientist is a good storyteller. During your data science project, you will have tons of data, tons of theories, and tons of results. Sometimes you'll feel as if you are lost in an ocean of data. If this happens, step back and think: What are we trying to achieve? For example, if your audience is a CEO and COO, they might need to make an executive decision in a couple of minutes based on your presentation. They aren't interested in learning about your ROC curve or in going through the 4 terabytes of data and 3,000 lines of your Python code.
Your goal is to give them direct recommendations based on your solid prediction algorithm and accurate results. We recommend that you create four or five slides where you clearly tell this story—storytelling backed by solid data and solid research.Visualization. Good data scientist needs to communicate results and recommendations using visualization. You cannot give 200-page report for someone to read. You need to present using pictures, images, charts, and graphs.
- Mindset. A good data scientist has a "hacker" mind—"hacker" being used here in a good way—and is relentlessly looking for patterns in the data set.
- Love thy data. You need to live with your data and let it tell you the story. Of course, there are many tools you can use to more fully understand the data, but just a superficial glance at it will give you lots of information.
What Can I Become?
Now it's time to decide. What type of data scientist should I become?
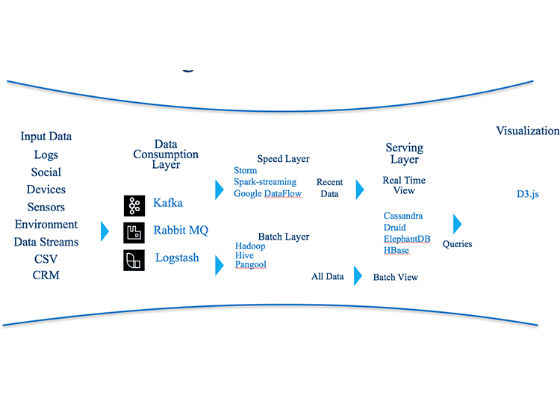
- Understand the pipeline. You need to start somewhere. You can be a Python developer working in a data science project. You can gather input data coming from logs, sensors, CSV file, and so on. You can write scripts to consume and ingest the incoming data. Data can be still or in-motion. You might decide to become a big data engineer working with technologies like Hadoop or Hive*. Or a machine learning algorithm specialist—someone who has mastered the skills and understands which algorithm works best under which problem. You can be a math genius, who can play with machine learning out-of-the-box algorithms and modify them according to your needs. You might become a data persistence expert. You might use SQL or NoSQL technologies to persist/serve data. Or you might become a data visualization expert and build dashboards and data stories using tools like Tableau. So check out the above pipeline one more time: from ingestion to visualization. Make an opportunity list. For example, "D3 expert, Python script expert, Spark master" and so on.
- Check out the job market. Look at the various job portals to get an idea of the current demand. How many jobs are there? What jobs are in highest demand? What is the salary structure? A casual glance at data science jobs in the Bay Area shows promising opportunities ►

- Understand yourself. You have explored the pipeline and type of jobs you can get. Now it's time to think about yourself and your skills. What do you enjoy most and what experience do you have? Do you love project management? Databases? Think about your previous success stories. Do you love writing complex scripts to correlate and manipulate data? Are you a visualization person, who is an expert at creating compelling presentations? Make a "love-to-do-list." For example, "love to code, love scripts, love Python."
- Create a match. Match your opportunity list with your love-to-do list and get on with the program. Data science is an ocean of information. Stay focused!!
For more such intel IoT resources and tools from Intel, please visit the Intel® Developer Zone
Source:https://software.intel.com/en-us/articles/data-science-is-an-ocean-of-information-stay-focused