Art’Em – Artistic Style Transfer to Virtual Reality Week 14 Update

Art’Em is an application that hopes to bring artistic style transfer to virtual reality. It aims to increment the stylization speed by using low precision networks.
In the last article [1], we discussed the strategy that could be adopted for implementing the low precision network and briefly looked at how convolution works. Today I will attempt to articulate how I tried to accelerate convolution operations using Compute Unified Device Architecture (CUDA) and explain other strategies for fast style transfer.
Optimization
You can look at this blog post [2] to learn how to create an optimization based neural style transfer algorithm in under 100 lines. By method of optimization, after 10,000 iterations of training on the Intel® Nervana™ platform we get the following result.

While there is no doubt that optimization based methods of style transfer, as discussed before, would give very high quality results, they will also take a long time. After simply looking at the speed of the network, we realize that no homemade optimization will bring the speed of a VGG16 much below 100ms. This means that as the number of iterations increase in the optimization based style transfer, the style transfer time will only rise.
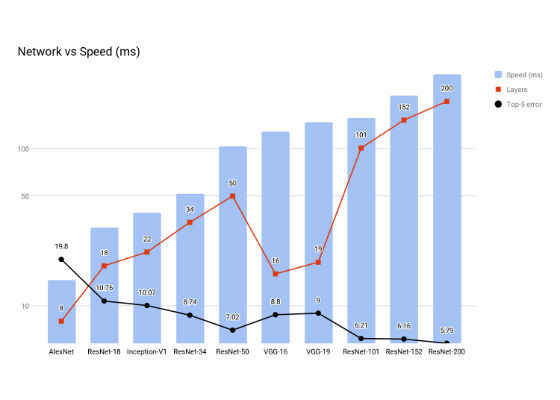
Note: Speed is the total time for a forward and backward pass on a Pascal Titan X with cuDNN 5.1.
We can see above that a good trade-off between accuracy and network speed is observed in ResNet-34. Even that will not give us reasonable style transfer speed. The iterative approach to stylization is extremely slow. This paper [3] suggests a generator network which can give us the ‘one-shot’ style transfer we can take advantage of.
The paper [3] roughly hypothesizes that there can exist a generator network which stylizes every content image to a specific style. While generator networks can give visually inferior and less diverse images than stylization-by-optimization, this will allow for significantly faster style transfer. For a particular style, the network is trained over the MS-COCO dataset. There are some clear disadvantages to this, one being that the entire network will have to be retrained on the MS-COCO dataset to adapt to a new style. However, we shall deal with this soon with a study on ‘Adaptive Instance Normalization’.
Stylization
With reference to the work by Logan Engstrom [4], I implemented a stripped down fast style transfer with a generator network following their work. My implementation used the original network but since my purpose would later be to operate at a fixed resolution it seemed fit to only use the transformation network and pair it with an image loader.

The optimized code when run on a GTX 1070 Graphics processing unit, gives around 5-6 frames per second at full VR resolution.
However, decreasing the size proportionately increases speed. Super-resolution can help here. The code typically takes webcam input and stylizes it. Running the same algorithm with a YouTube video and PIL ImageGrab utility gives the output below. Note that the output has been scaled down in resolution.

Pruning the model could give much faster results. Training for these models will be performed on the Intel® AI DevCloud.
The generator network by Logan Engstrom [4] utilizes 3 convolutional layers, 5 residual blocks, and 3 transposed convolutional layers.
Simplification of this model might give much faster results.

A residual block (left) deals with the problem of scaling a normal CNN faces. For instance, increasing the depth of a CNN might degrade results irrespective of overfitting. However, If too many residual blocks are added, they can simply learn an ‘identity mapping’ (Output = Input).
To learn more about transposed convolution, do check out this [5] excellent resource.
Throughput
In an attempt to implement XNOR-convolution using CUDA programming, I designed a simple kernel for binary convolution and general full precision convolution. It is important to note while parallelization was done per channel, the channel convolution themselves have not been parallelized. The speed could be increased multiple times if the maximum available grid size was utilized. The benchmark below is simply to demonstrate the difference between the two methods. Similar scaling should be observed if the kernel is optimized.
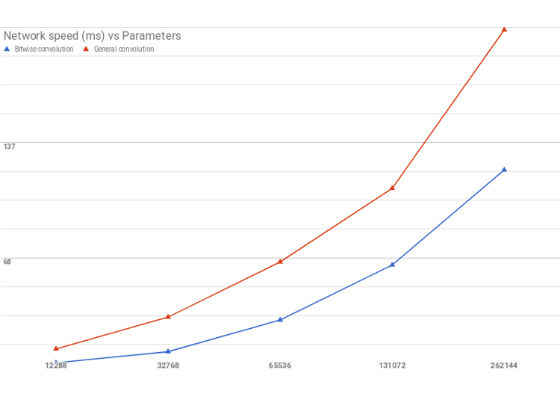
However, too many technical difficulties were faced by me when trying to integrate my code with deep learning frameworks. I thus decided to benchmark the effectiveness of XNOR-convolution when compared to full precision convolution. The results were not as significant as that for fully connected networks because of the fact that the complexity of convolution is not reduced as much as it is for matrix multiplication in XNOR-nets. The results however still indicated notable speedup using bitwise convolution.
This approach might increase the performance of the network by a lot but remains unimplementable for me. But using a full precision generator network and training it on the Intel® Nervana™ DevCloud remains a feasible option.
Adaptive Instance Normalization
While in the initial implementation of style transfer, we used instance normalization and a generator network, a big limitation was the fact that every generator network corresponds to only one style transformation. This limits us in terms of what the user can experience greatly, VR or not.
A brilliant research paper [6] has recently found a good way to adapt to all styles. It has 3 components, a VGG Encoder, an Adaptive Instance normalization block and a decoder. The image below summarizes the method.
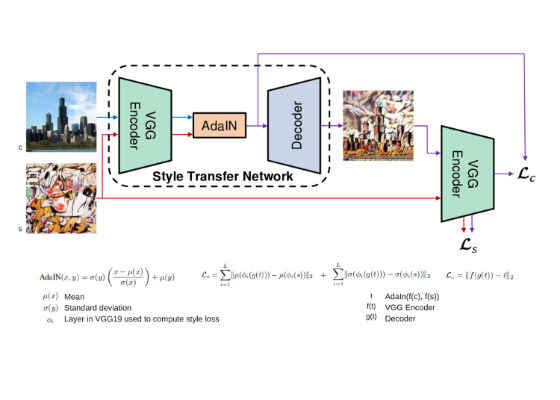
The AdaIn transforms the content input from the encoder to align with the channel-wise mean and variance of the style image.
The network is trained on MS-COCO dataset along with the Wikiart Images dataset[7]. Using a pre-trained network gives very decent results. Similar results can be found at this link[8]. Implementing this model was found to be much more expensive in terms of time when compared to a single style. Since every stylized model was around 20 megabytes, going with the concept of Instance normalization for quick stylization seemed to be the better option.
For more such intel IoT resources and tools from Intel, please visit the Intel® Developer Zone
Source: https://software.intel.com/en-us/blogs/2017/12/19/art-em-artistic-style-transfer-to-virtual-reality-week-14-update