TensorFlow Optimizations on Modern Intel Architecture

Intel: Elmoustapha Ould-Ahmed-Vall, Mahmoud Abuzaina, Md Faijul Amin, Jayaram Bobba, Roman S Dubtsov, Evarist M Fomenko, Mukesh Gangadhar, Niranjan Hasabnis, Jing Huang, Deepthi Karkada, Young Jin Kim, Srihari Makineni, Dmitri Mishura, Karthik Raman, AG Ramesh, Vivek V Rane, Michael Riera, Dmitry Sergeev, Vamsi Sripathi, Bhavani Subramanian, Lakshay Tokas, Antonio C Valles
Google: Andy Davis, Toby Boyd, Megan Kacholia, Rasmus Larsen, Rajat Monga, Thiru Palanisamy, Vijay Vasudevan, Yao Zhang
TensorFlow* is a leading deep learning and machine learning framework, which makes it important for Intel and Google to ensure that it is able to extract maximum performance from Intel’s hardware offering. This paper introduces the Artificial Intelligence (AI) community to TensorFlow optimizations on Intel® Xeon® and Intel® Xeon Phi™ processor-based platforms. These optimizations are the fruit of a close collaboration between Intel and Google engineers announced last year by Intel’s Diane Bryant and Google’s Diane Green at the first Intel AI Day.
We describe the various performance challenges that we encountered during this optimization exercise and the solutions adopted. We also report out performance improvements on a sample of common neural networks models. These optimizations can result in orders of magnitude higher performance. For example, our measurements are showing up to 70x higher performance for training and up to 85x higher performance for inference on Intel® Xeon Phi™ processor 7250 (KNL). Intel® Xeon® processor E5 v4 (BDW) and Intel Xeon Phi processor 7250 based platforms, they lay the foundation for next generation products from Intel. In particular, users are expected to see improved performance on Intel Xeon (code named Skylake) and Intel Xeon Phi (code named Knights Mill) coming out later this year.
Optimizing deep learning models performance on modern CPUs presents a number of challenges not very different from those seen when optimizing other performance-sensitive applications in High Performance Computing (HPC):
1. Code refactoring needed to take advantage of modern vector instructions. This means ensuring that all the key primitives, such as convolution, matrix multiplication, and batch normalization are vectorized to the latest SIMD instructions (AVX2 for Intel Xeon processors and AVX512 for Intel Xeon Phi processors).
2. Maximum performance requires paying special attention to using all the available cores efficiently. Again this means looking at parallelization within a given layer or operation as well as parallelization across layers.
3. As much as possible, data has to be available when the execution units need it. This means balanced use of prefetching, cache blocking techniques and data formats that promote spatial and temporal locality.
To meet these requirements, Intel developed a number of optimized deep learning primitives that can be used inside the different deep learning frameworks to ensure that we implement common building blocks efficiently. In addition to matrix multiplication and convolution, these building blocks include:
- Direct batched convolution
- Inner product
- Pooling: maximum, minimum, average
- Normalization: local response normalization across channels (LRN), batch normalization
- Activation: rectified linear unit (ReLU)
- Data manipulation: multi-dimensional transposition (conversion), split, concat, sum and scale.
Refer to this article for more details on these Intel® Math Kernel Library for Deep Neural Networks (Intel® MKL-DNN) optimized primitives.
In TensorFlow, we implemented Intel optimized versions of operations to make sure that these operations can leverage Intel MKL-DNN primitives wherever possible. While, this is a necessary step to enable scalable performance on Intel® architecture, we also had to implement a number of other optimizations. In particular, Intel MKL uses a different layout than the default layout in TensorFlow for performance reasons. We needed to ensure that the overhead of conversion between the two formats is kept to a minimum. We also wanted to ensure that data scientists and other TensorFlow users don’t have to change their existing neural network models to take advantage of these optimizations.
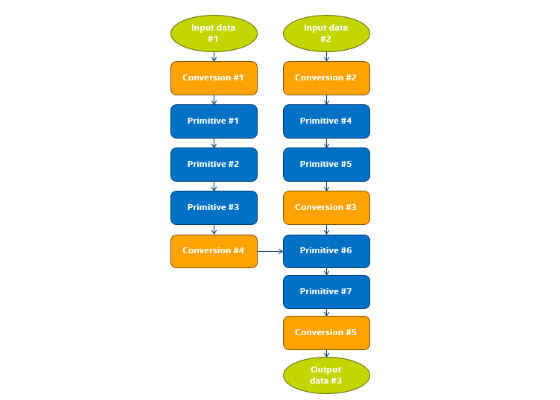
Graph Optimizations
We introduced a number of graph optimization passes to:
1. Replace default TensorFlow operations with Intel optimized versions when running on CPU. This ensures that users can run their existing Python programs and realize the performance gains without changes to their neural network model.
2. Eliminate unnecessary and costly data layout conversions.
3. Fuse multiple operations together to enable efficient cache reuse on CPU.
4. Handle intermediate states that allow for faster backpropagation.
These graph optimizations enable greater performance without introducing any additional burden on TensorFlow programmers. Data layout optimization is a key performance optimization. Often times, the native TensorFlow data format is not the most efficient data layout for certain tensor operations on CPUs. In such cases, we insert a data layout conversion operation from TensorFlow’s native format to an internal format, perform the operation on CPU, and convert operation output back to the TensorFlow format. However, these conversions introduce a performance overhead and should be minimized. Our data layout optimization identifies sub-graphs that can be entirely executed using Intel MKL optimized operations and eliminates the conversions within the operations in the sub-graph. Automatically inserted conversion nodes take care of data layout conversions at the boundaries of the sub-graph. Another key optimization is the fusion pass that automatically fuses operations that can be run efficiently as a single Intel MKL operation.
Other Optimizations
We have also tweaked a number of TensorFlow framework components to enable the highest CPU performance for various deep learning models. We developed a custom pool allocator using existing pool allocator in TensorFlow. Our custom pool allocator ensures that both TensorFlow and Intel MKL share the same memory pools (using the Intel MKL imalloc functionality) and we don’t return memory prematurely to the operating system, thus avoiding costly page misses and page clears. In addition, we carefully tuned multiple threading libraries (pthreads used by TensorFlow and OpenMP used by Intel MKL) to coexist and not to compete against each other for CPU resources.
Performance Experiments
Our optimizations such as the ones discussed above resulted in dramatic performance improvements on both Intel Xeon and Intel Xeon Phi platforms. To illustrate the performance gains we report below our best known methods (or BKMs) together with baseline and optimized performance numbers for three common ConvNet benchmarks.
1. The following parameters are important for performance on Intel Xeon (codename Broadwell) and Intel Xeon Phi (codename Knights Landing) processors and we recommend tuning them for your specific neural network model and platform. We have carefully tuned these parameters to gain maximum performance for convnet-benchmarks on both Intel Xeon and Intel Xeon Phi processors.
1. Data format: we suggest that users can specify the NCHW format for their specific neural network model to get maximum performance. TensorFlow default NHWC format is not the most efficient data layout for CPU and it results in some additional conversion overhead.
2. Inter-op / intra-op: we also suggest that data scientists and users experiment with the intra-op and inter-op parameters in TensorFlow for optimal setting for each model and CPU platform. These settings impact parallelism within one layer as well as across layers.
3. Batch size: batch size is another important parameter that impacts both the available parallelism to utilize all the cores as well as working set size and memory performance in general.
4. OMP_NUM_THREADS: maximum performance requires using all the available cores efficiently. This setting is especially important for performance on Intel Xeon Phi processors since it controls the level of hyperthreading (1 to 4).
5. Transpose in Matrix multiplication: for some matrix sizes, transposing the second input matrix b provides better performance (better cache reuse) in Matmul layer. This is the case for all the Matmul operations used in the three models below. Users should experiment with this setting for other matrix sizes.
6. KMP_BLOCKTIME: users should experiment with various settings for how much time each thread should wait after completing the execution of a parallel region, in milliseconds.
Example settings on Intel® Xeon® processor (codename Broadwell – 2 Sockets – 22 Cores)

Example settings on Intel® Xeon Phi™ processor (codename Knights Landing – 68 Cores)

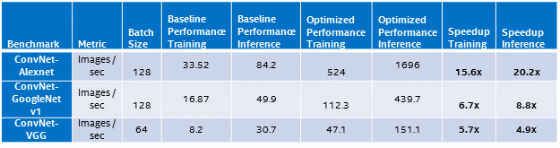
1. Performance results on Intel® Xeon® processor (codename Broadwell – 2 Sockets – 22 Cores)
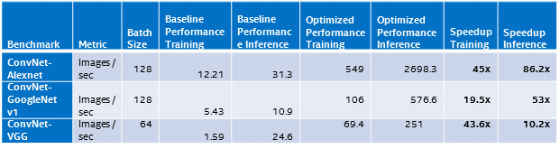
2. Performance results on Intel® Xeon Phi™ processor (codename Knights Landing – 68 cores)
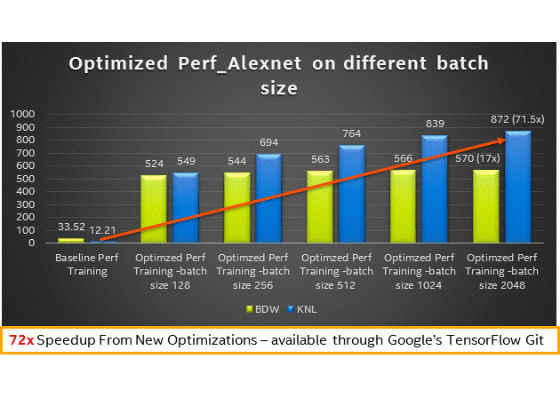
3. Performance results with different batch sizes on sizes on Intel® Xeon® processor (codename Broadwell) and Intel® Xeon Phi™ processor (codename Knights Landing) – Training
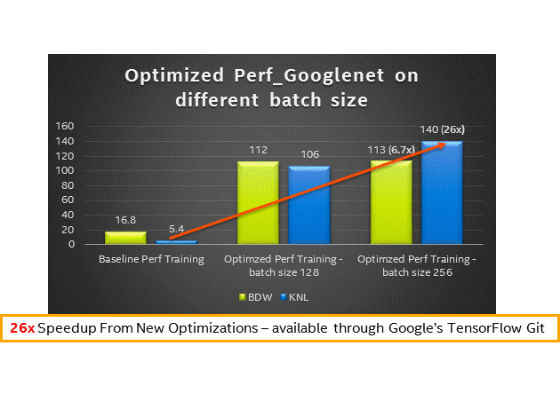
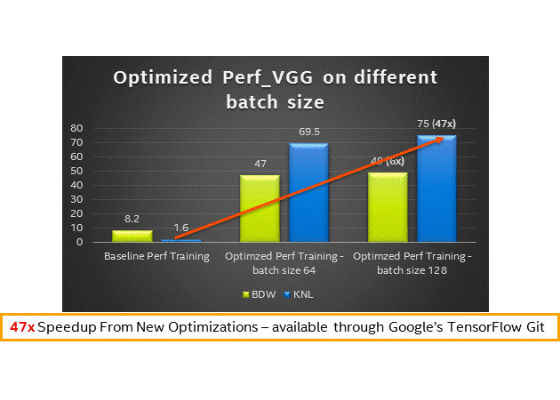
Building and Installing TensorFlow with CPU Optimizations
1. Run "./configure" from the TensorFlow source directory, and it will download latest Intel MKL for machine learning automatically in tensorflow/third_party/mkl/mklml if you select the options to use Intel MKL.
2. Execute the following commands to create a pip package that can be used to install the optimized TensorFlow build.
- PATH can be changed to point to a specific version of GCC compiler:
export PATH=/PATH/gcc/bin:$PATH
- LD_LIBRARY_PATH can also be changed to point to new GLIBC :
export LD_LIBRARY_PATH=/PATH/gcc/lib64:$LD_LIBRARY_PATH.
- Build for best performance on Intel Xeon and Intel Xeon Phi processors:
bazel build –config=mkl –copt=”-DEIGEN_USE_VML” -c opt //tensorflow/tools/pip_package:
build_pip_package
3. Install the optimized TensorFlow wheel
1. bazel-bin/tensorflow/tools/pip_package/build_pip_package ~/path_to_save_wheel
pip install –upgrade –user ~/path_to_save_wheel /wheel_name.whl
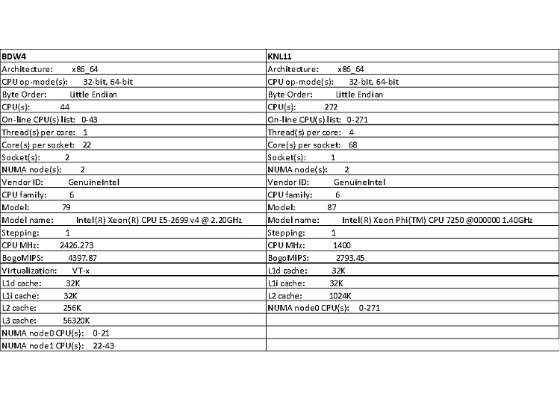
System Configuration
What It Means for AI
Optimizing TensorFlow means deep learning applications built using this widely available and widely applied framework can now run much faster on Intel processors to increase flexibility, accessibility, and scale. The Intel Xeon Phi processor, for example, is designed to scale out in a near-linear fashion across cores and nodes to dramatically reduce the time to train machine learning models. And TensorFlow can now scale with future performance advancements as we continue enhancing the performance of Intel processors to handle even bigger and more challenging AI workloads.
The collaboration between Intel and Google to optimize TensorFlow is part of ongoing efforts to make AI more accessible to developers and data scientists, and to enable AI applications to run wherever they’re needed on any kind of device—from the edge to the cloud. Intel believes this is the key to creating the next-generation of AI algorithms and models to solve the most pressing problems in business, science, engineering, medicine, and society.
This collaboration already resulted in dramatic performance improvements on leading Intel Xeon and Intel Xeon Phi processor-based platforms. These improvements are now readily available through Google’s TensorFlow GitHub repository. We are asking the AI community to give these optimizations a try and are looking forward to feedback and contributions that build on them.
For more such intel IoT resources and tools from Intel, please visit the Intel® Developer Zone
Source:https://software.intel.com/en-us/articles/tensorflow-optimizations-on-modern-intel-architecture