How to Use Intel AI Playground Effectively and Run LLMs Locally (Even Offline)
")
Intel’s AI Playground is one of the easiest ways to experiment with large language models (LLMs) on your own computer—without needing to write a single line of code. It’s a sleek app for Windows that combines chat-based AI, image generation, embeddings, and local model hosting, all in one place. Best of all? Once set up, it can run completely offline.
The app is designed to run on systems equipped with an Intel Core Ultra-H or Ultra-V processor, or a discrete Intel Arc GPU (Series A or B) with at least 8 GB of VRAM. This guide and testing were done on the Lenovo 14-inch Yoga Slim 7i Aura Edition powered by an Intel Lunar Lake Core Ultra 7 processor, which met the hardware requirements for running the app locally.
For those unfamiliar, Intel’s Lunar Lake architecture features integrated LPDDR5X memory soldered onto the CPU package. This design allows the system to share memory between the CPU and GPU, reducing latency and increasing bandwidth. The result is enhanced integrated GPU performance and improved power efficiency, particularly beneficial for thin-and-light laptops.
Downloading and Installing Intel AI Playground
Step 1: Download the app
Go to the official Intel AI Playground GitHub page and download the latest Windows installer.
Step 2: Install
Run the installer and follow the instructions. It will install the base app quickly, but the first time you open it, it’ll need to download some essential components like:
- Python and Conda: Python is the programming language that powers most of the app’s backend, while Conda helps manage all the dependencies neatly.
- Intel’s IPEX-LLM backend: This is Intel’s optimisation layer that ensures LLMs run faster and more efficiently on Intel hardware.
- ComfyUI for image generation: A visual, node-based interface that lets you customise how images are generated from text prompts.
- Model inference engines: These are the tools that actually run the AI models and turn your inputs into real-time responses or images.
Make sure your internet connection is stable during this step. Sometimes, the process will appear stuck on the installation screen so give it time to finish. If after giving it time it is still not proceeding further with the installation then simply close the application and restart it again. Once the installation finishes, the app is ready to use.
Using the Built-in AI Chat Models
Intel AI Playground comes preloaded with a few large language models that are ready to use as soon as the app is installed. These include Phi-3 Mini, a lightweight model suitable for general-purpose tasks, Qwen2-1.5B, a versatile 1.5 billion parameter model designed to handle a broad range of applications, and Mistral 7B, a more capable 7 billion parameter model offering enhanced language understanding. All of these models are provided in quantized formats, such as INT4, to run efficiently on Intel Arc GPUs and Core Ultra processors without compromising too much on performance.
For image generation, Intel AI Playground includes two powerful models by default. DreamShaper 8 is used for standard image generation tasks, delivering visually appealing results with a balanced aesthetic. On the other hand, Juggernaut XL v9 is geared toward high-definition (HD) image generation, making it ideal for users looking to create more detailed and refined visuals. Both models are integrated into the app’s Create tab, allowing users to start generating images from text prompts right out of the box.
Step 1: Open the Playground and go to the Answer tab
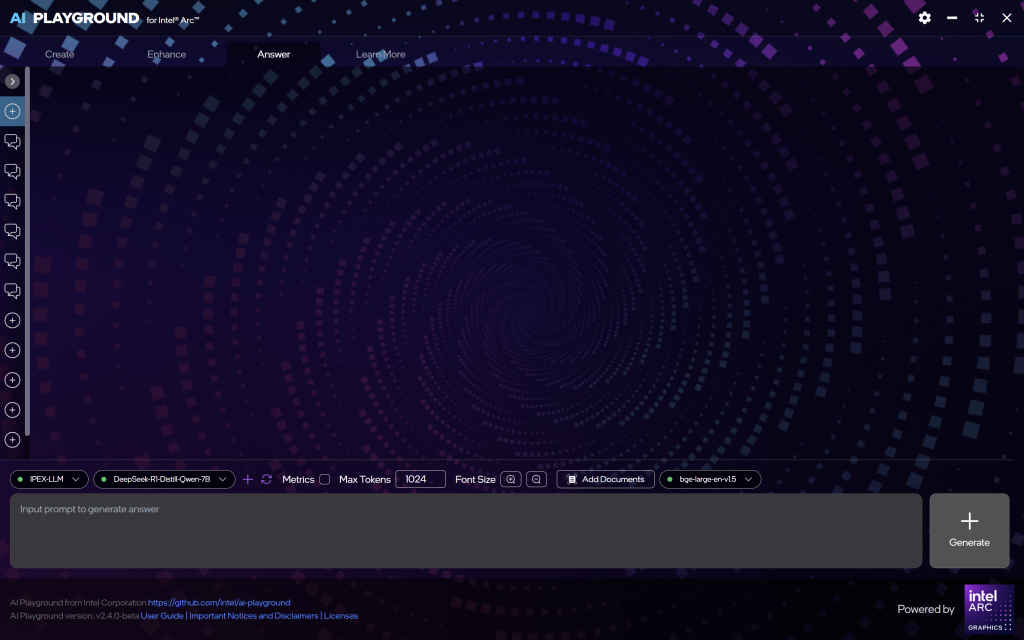
This is where all chat-based models live.
Step 2: Select a model
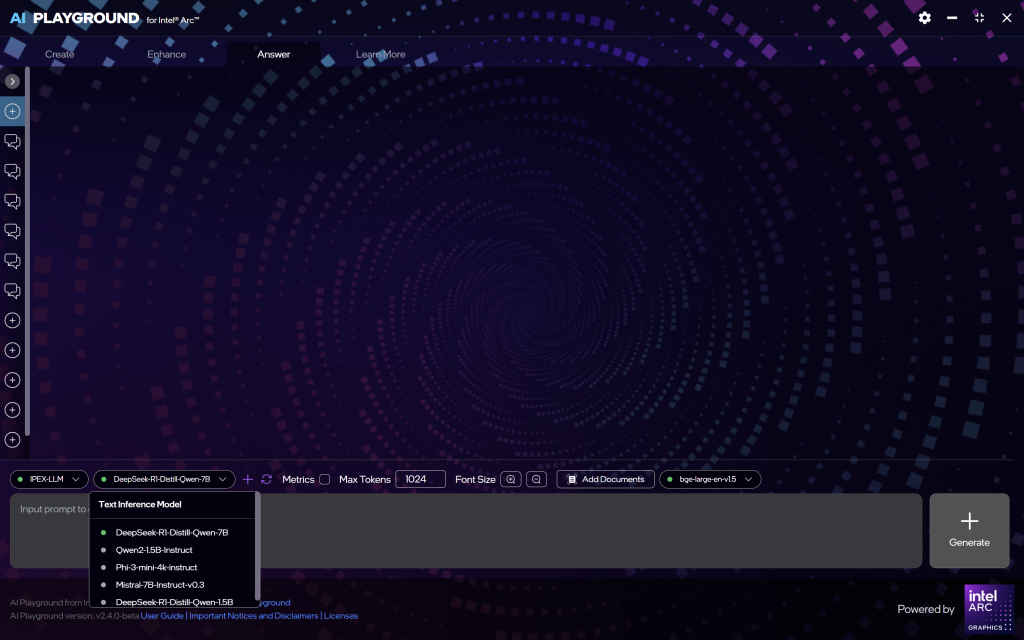
In the “Answer” tab, the following language models are preloaded:
- Phi-3 Mini
- Qwen2-1.5B
- Mistral 7B
These models are available in quantized formats (e.g., INT4) to ensure efficient performance on Intel Arc GPUs and Core Ultra processors.
In the “Create” tab, the following image generation models are included:
- DreamShaper 8: Used for standard image generation tasks.
- Juggernaut XL v9: Employed for high-definition (HD) image generation.
These models enable users to generate images from text prompts directly within the application.
Step 3: Start chatting
Type a question or prompt, and the model will respond instantly—all on your device. No internet needed after the first setup. You also have the option to upload a PDF, document, spreadsheet, or any other file into the chat and interact directly with the LLM about the information it contains.
Also read: ALOGIC Fusion Pro Nexus USB-C Universal Video Dock Review
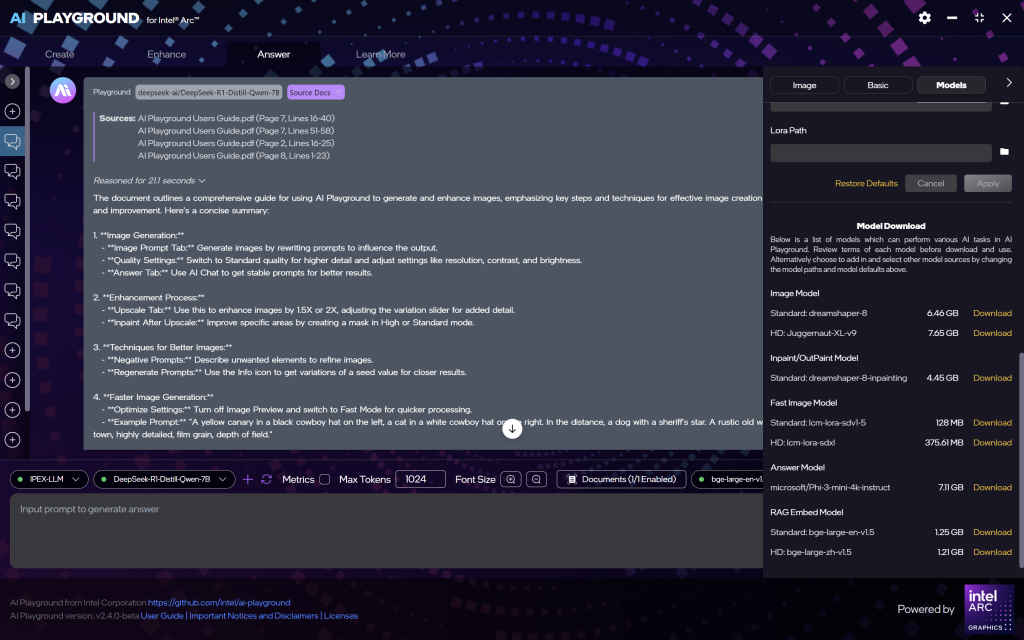
Running Custom or External Models
Intel AI Playground offers flexibility for users to load their own models, including those in GGUF and GGML formats. This allows for a broader range of language models beyond the preloaded options.
Loading Custom Models
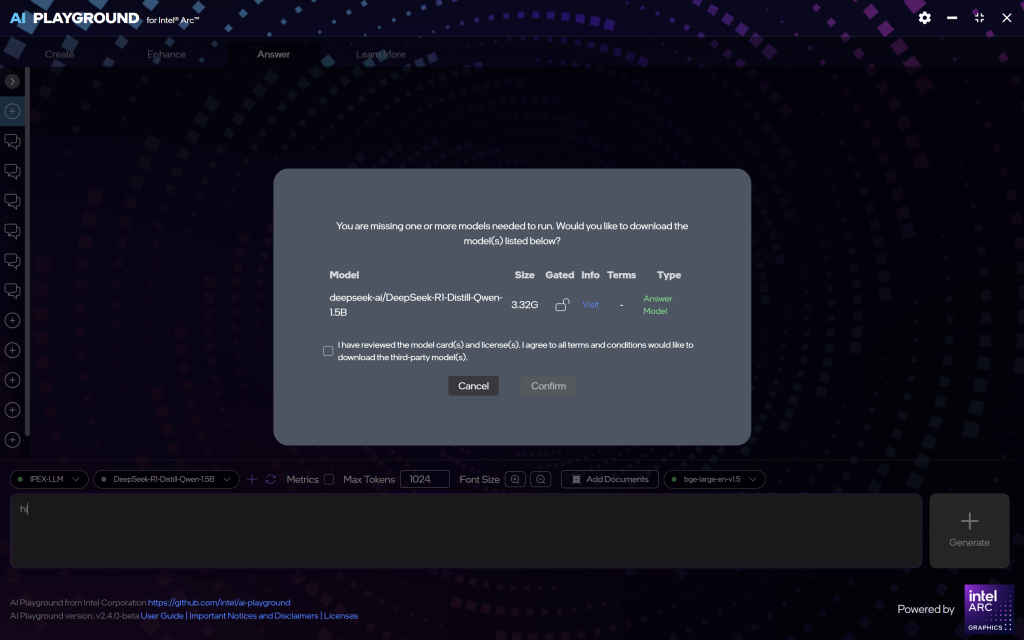
To add a custom model:
- Access the Model Management Interface: Navigate to the “Settings” or “Model Management” section within the AI Playground application.
- Add Model: Click on the “Add Model” button.
- Specify Model Source: You can input either a Hugging Face model ID or a local file path to the model you wish to load.
- Configure Model Settings: Adjust settings such as quantization format (e.g., INT4), context length, and device preferences to optimize performance.
- Save and Load: Save the configuration and load the model into the application.
This modular design allows users to experiment with various models, tailoring the AI Playground to specific needs.
Compatibility Considerations
When loading custom models, ensure that your hardware meets the requirements, especially regarding GPU memory and processing capabilities. Intel Arc GPUs with at least 8 GB of memory are recommended for optimal performance.
Utilizing Embeddings and Retrieval-Augmented Generation (RAG)
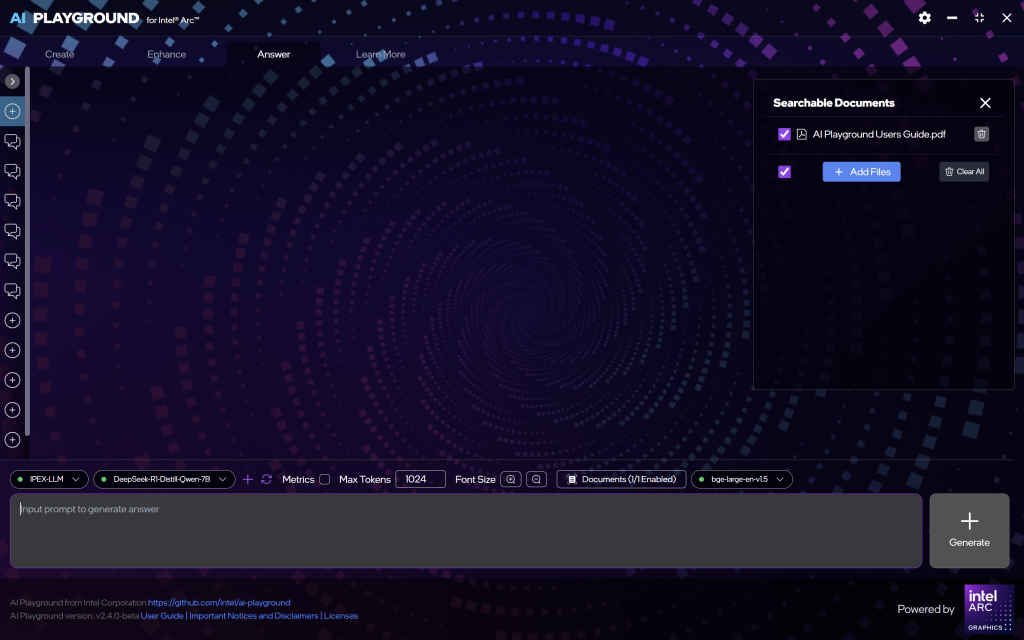
This section helps you understand and use two powerful features built into Intel AI Playground: embeddings and RAG (Retrieval-Augmented Generation). These tools are especially useful when you want to ask questions about documents you’ve uploaded—like PDFs, research reports, or spreadsheets—and get accurate, AI-generated answers based on their content.
Intel AI Playground supports both these technologies, enabling advanced document-based question-answering workflows right on your local machine.
What Are Embeddings?
Embeddings convert text (like paragraphs, sentences, or entire documents) into numerical vectors that capture their meaning. This lets the AI “understand” and compare pieces of information—even if they use different words but mean similar things.
How RAG Works in AI Playground
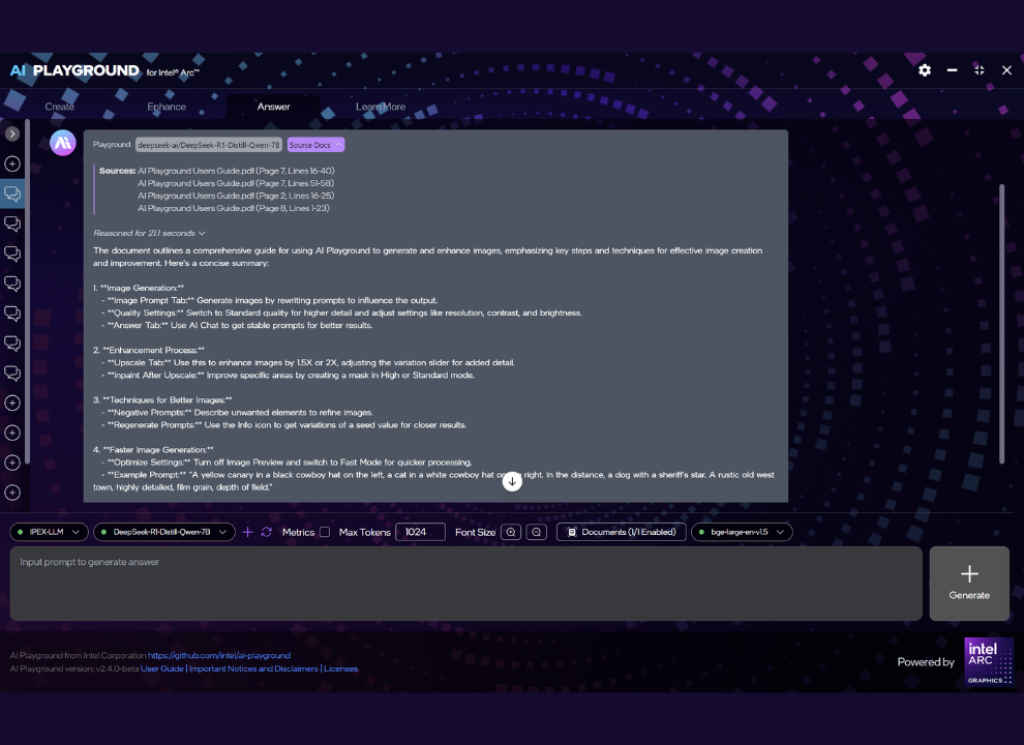
RAG, or Retrieval-Augmented Generation, combines search + AI generation. Here’s how it works in this app:
- You upload documents (PDFs, notes, etc.)
- The app scans and embeds them to understand their structure and meaning.
- When you ask a question, the AI retrieves the most relevant chunks from those documents.
- It then generates an answer based on those chunks, giving you a much more accurate response.
This setup is incredibly useful for tasks like:
- Extracting insights from reports
- Summarising client documents
- Answering questions from internal knowledge bases
Best Practices & Performance Tips
When it comes to hardware optimisation, two key areas can make a noticeable difference in your experience with Intel AI Playground. First, GPU utilisation: make sure your Intel Arc GPU drivers are fully up to date. This helps the app take full advantage of hardware acceleration, allowing models to run more smoothly and respond faster. Second, memory management is crucial, especially if you’re working with larger models or running multiple tasks in parallel. Keeping an eye on your system’s RAM usage ensures the app doesn’t slow down or crash unexpectedly, giving you a more stable and efficient workflow.
Intel AI Playground isn’t trying to reinvent the wheel, it just makes running local AI tools a lot less painful. Whether you’re testing out language models, generating art, or digging through documents offline, it wraps everything in a clean interface that doesn’t get in your way. Once you’ve got it set up, it’s surprisingly low-maintenance. And while it’s not perfect, for anyone curious about LLMs or looking to keep their work local, it’s a solid place to start messing around.
Also read: ASUS ExpertBook P1 First Impressions: A No-Nonsense Business Workhorse with Surprising Power