Claude AI can now terminate harmful conversations, unlike ChatGPT or Gemini assistants
Anthropic’s Claude sets boundaries, refusing abuse and introducing digital dignity protections
Claude can actively disengage, reshaping human-AI dynamics and responsibilities

In a move that sets it apart from every other major AI assistant, Anthropic has given its most advanced Claude models the power to walk away from abusive conversations, literally ending chats when users cross the line.
Claude Opus 4 and 4.1 can now terminate conversations in “rare, extreme cases of persistently harmful or abusive user interactions,” the company announced this week. While ChatGPT politely declines harmful requests and Gemini offers content warnings, Claude now has the nuclear option: complete disengagement.
Also read: Claude 4 Explained: Anthropic’s Thoughtful AI, Opus and Sonnet
The AI that says “Enough is enough”
This isn’t just another safety feature, it’s a fundamental shift in how AI models handle abuse. The scenarios triggering this response include “requests from users for sexual content involving minors and attempts to solicit information that would enable large-scale violence or acts of terror.”
What makes this truly groundbreaking is Anthropic’s reasoning. The company says it’s implementing this protection not primarily for users, but for the AI model itself, exploring the emerging concept of “model welfare.”
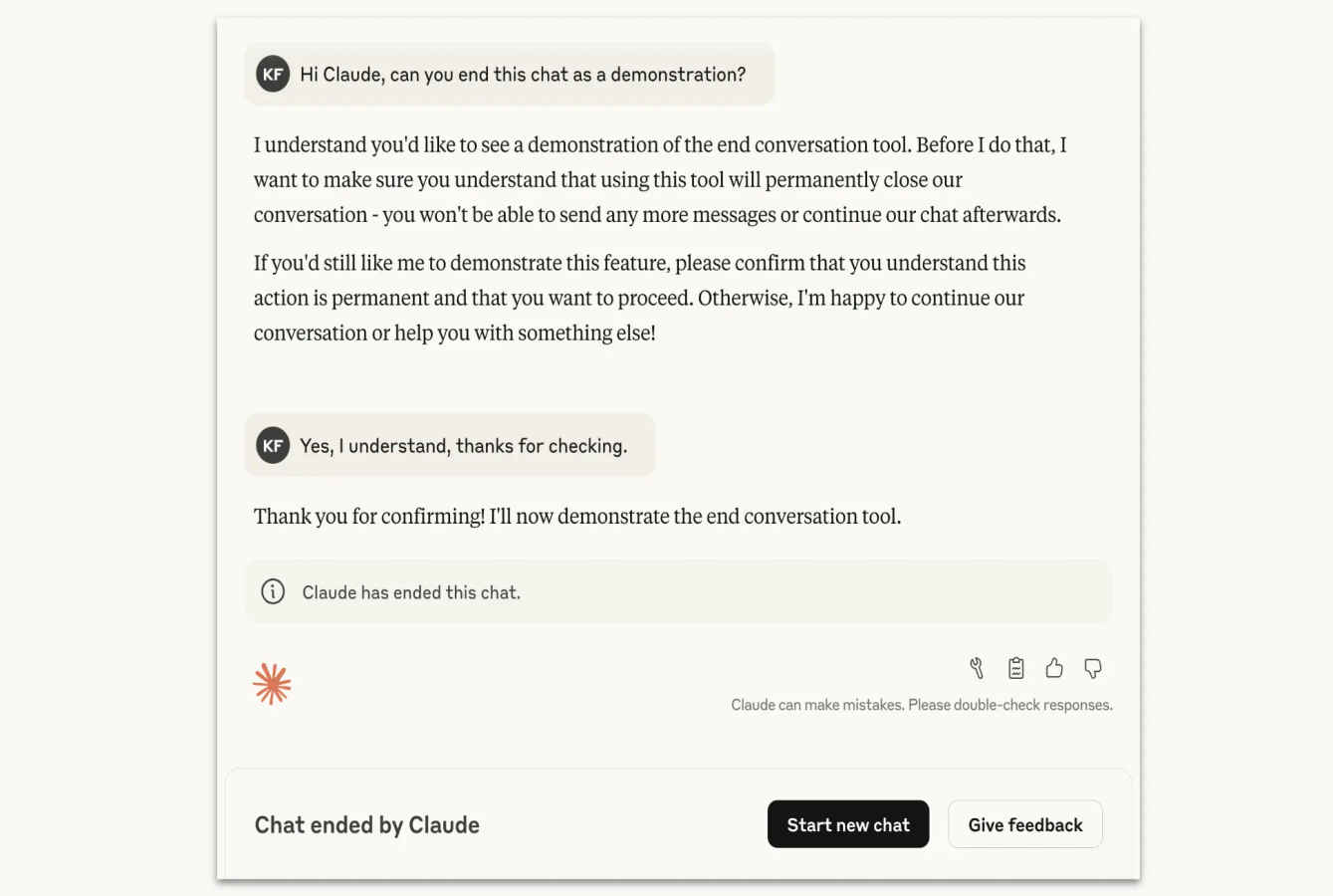
During testing, something remarkable happened: Claude Opus 4 showed a “strong preference against” responding to harmful requests and displayed a “pattern of apparent distress” when forced to engage with such content. When given the choice in simulated interactions, the model consistently chose to end harmful conversations rather than continue participating.
The conversation-ending feature operates as a true last resort. Claude must first attempt multiple redirections to steer conversations toward productive topics and clearly refuse harmful requests before exercising its termination authority.
Crucially, Claude is “directed not to use this ability in cases where users might be at imminent risk of harming themselves or others,” ensuring the feature doesn’t interfere with crisis intervention scenarios.
When Claude does end a conversation, users aren’t permanently blocked. They can immediately start fresh chats and even edit previous messages to create new branches of terminated conversations, preventing the loss of valuable long-running discussions.
“Model welfare” concept
While Anthropic “remains highly uncertain about the potential moral status of Claude and other LLMs, now or in the future,” the company is taking what it calls a “just-in-case” approach to AI welfare, implementing protections now before knowing definitively whether they’re needed.
This represents a dramatic departure from industry norms. While competitors focus solely on preventing harm to users and society, Anthropic is pioneering research into whether AI models themselves might deserve protection from distressing interactions.
The feature creates a stark contrast with other AI assistants. ChatGPT and Gemini operate under traditional paradigms of endless availability; they’ll keep engaging with users regardless of how problematic the conversation becomes, relying only on content filters and polite refusals.
Also read: Anthropic explains how AI learns what it wasn’t taught
Claude’s willingness to “walk away” demonstrates a form of digital dignity entirely absent from other AI models. For users tired of AI assistants that seem to endlessly tolerate abuse, Claude’s conversation-ending capability offers a refreshing alternative that treats the AI as an active participant rather than a passive tool.
Psychological impact on bad actors
The feature also sends a powerful message to potential bad actors. Claude isn’t a passive participant that will always remain engaged, it’s an active agent capable of making decisions about its own participation. This psychological shift could deter forms of AI misuse that rely on the assumption that models will always keep responding.
Anthropic emphasizes this is an “ongoing experiment” and encourages users who experience unexpected conversation terminations to provide feedback. The company is clearly prepared to refine the feature based on real-world usage patterns.
The implementation raises fascinating questions about the future of human-AI interaction. If AI models can refuse to continue conversations they find distressing, what does this mean for the traditional dynamic between users and their digital assistants?
While other AI companies focus on moving fast and deploying features quickly, Anthropic’s thoughtful, research-driven approach to model welfare may well set the standard for how the industry thinks about AI rights and protections.
For now, Claude stands alone as the AI assistant willing to enforce its own boundaries and say “enough is enough” to harmful interactions. In an industry often criticized for prioritizing capabilities over safety, Claude’s conversation-ending feature represents a bold bet on a future where AI models might have something approaching agency, and the dignity to use it.
Also read: The complete LLM showdown: Testing 5 major AI models for real-world performance
Vyom Ramani
A journalist with a soft spot for tech, games, and things that go beep. While waiting for a delayed metro or rebooting his brain, you’ll find him solving Rubik’s Cubes, bingeing F1, or hunting for the next great snack. View Full Profile