JaegerMonkey development diary – shaping up THE JavaScript engine for Firefox 4.0

…thanks to Kshtij Sobti
Breaking in with Firefox version 3.5, TraceMonkey was doing its job well. Pretty well indeed; it surpassed its ancestor, the SpiderMonkey engine by being 30-40 times faster in some cases. But when the competition is concerned, it’s no match for Chrome’s, Safari’s and Opera’s JavaScript engines. While the WebKit-based browsers are showing great improvement in JavaScript performance with V8 (for Chrome) and SquirrelFish (also known as Nitro, for Safari) engines, and even Opera is striking with their revolutionary Carakan engine – it’s time for the Firefox guys to show some moves. Well, the good news is – they are about to…
{kind=link}
Understanding the status quo…
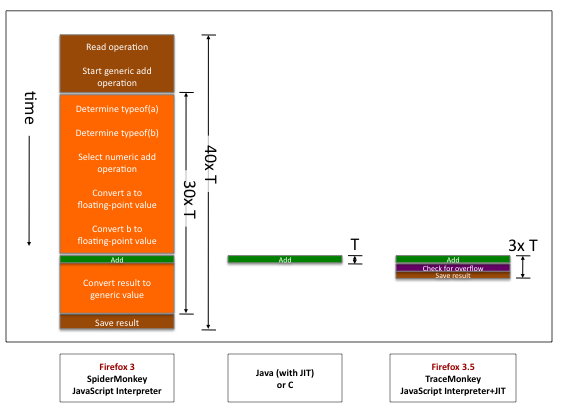
Mozilla’s JavaScript team is on a mission to renovate the JavaScript engine for the upcoming major release of Firefox. When version 3.5 landed with major JS performance upgrades including the TraceMonkey (TM) engine, the future of Firefox’s JS engine seemed to lie in more and more optimizations to the TraceMonkey engine. But over time, it has become clear that TraceMonkey can only take Mozilla so far.
It gave a throttle to the legacy SpiderMonkey (SM) engine for sure, but TM isn’t a standalone engine itself, it is merely a performance booster. So, for some parts of JS compiling, TM has to take help from the legacy engine, making the overall performance suffer. To understand the combination better, let us put it like- trying to go to Kanyakumari, by taking a flight to Chennai to save time, and then walking on from there! The tracing accomplished by TraceMonkey can give incredible boosts in performance, but when it doesn’t work, Firefox falls back to the much slower older SpiderMonkey interpreter engine!
In this era of cut-throat competition, where each browser is trying to juice it’s engine for the most performance it can give, Firefox is seriously lagging behind. SpiderMonkey is no match for current generation engines in Chrome, Safari, Opera and even Internet Explorer 9! An alternate to the baseline interpreter in SpiderMonkey is sorely needed. Luckily Mozilla is well on this task, and will Firefox 4.0 they aim to bring Firefox’s JavaScript performance to today’s standards, if not better.
That is what JaegerMonkey (alt. JägerMonkey) is all about.
JaegerMonkey, from a layman’s perspective…
Started back in January 2010, JaeagerMonkey is to eventually become the JavaScript engine for Firefox 4.0. After evolving from SpiderMonkey to TraceMonkey, JeagerMonkey sounds like a further evolution of TraceMonkey, but it’s not. Actually, it’s a spin off build from SpiderMonkey itself, to implement the Method JIT and many optimization techniques, which will multiply the performance, even without having a tracer included. So, instead of walking from Chennai, it catches a train to Kanyakumari – and by the time we are telling you this, the train has become from a steam engined one to a Shinkansen bullet train, over the course of last six months.
The implementation of JaegerMonkey (JM) will be as a replacement for SpiderMonkey, and integrated with TraceMonkey. So that, in those cases where TraceMonkey used to leave the job in the hands of SpideMonkey, it will instead fall back to JaegerMonkey. As of now, JM and TM are equally fast, but JM excels in compiling those codes that TM fails to work upon. So that when these two are integrated, the combined system will hopefully have no Achilles Heel.
Hence, simplified…
| SpiderMonkey | The legacy JavaScript compiler for Firefox (the first ever JavaScript engine, written by the Father of JavaScript, Brendan Eich himself). |
| TraceMonkey | The tracing JIT compiler added with SpiderMonkey in Firefox 3.5, to boost its performance. |
| JaegerMonkey | The new iteration of baseline JavaScript compiler for Firefox 4.0. Currently in development by Mozilla JavaScript team. It will replace the SpiderMonkey engine, to enhance native JS competence. |
With this much said, most of you may consider it the end of the story – but for geek pleasure, we will go further ahead dissecting the innards of those monkeys. So, click ‘Next‘ with caution; if you have a tendency for heart-attacks or allergy to techno-babble, advance no more!
Where TraceMonkey Fails?
The trouble with TraceMokey (TM) is that- although the engine has a great efficiency handling code that can be traced well, but when dealing with code that can not be traced, it falls back to the base JavaScript interpreter.
For any given code being executed by Firefox the execution will be happening in the old SpiderMonkey interpreter engine. The tracing engine will keep a look out for repeated code, and in such cases try to optimize it using the tracing JIT. If this works, great, if it doesn’t we’ve just wasted some time. Also in cases where the code uses an eval() function, TM fails (as it requires the variables and types to be predefined), and the interpreter has to do the job.
So, as it is prominent, these events cause two-fold delays; one for the trials with TM which eventually ends up fruitless, and the other is for the default interpreter, which takes more time than a polished sophisticated JS engine.
What is JaegerMonkey?
Faced with this huge performance gap between their two engine, it was clear that simply making the faster engine even faster wont cut it. As long as it is falling back to the old interpreter the overall speed won’t improve appreciably. Mozilla’s Tracing JIT has already gained a respectable standard when executing the code it works well with, and with such codes it manages to beat other browsers even with its current engine. Now something needed to be done about the slower engine.
The concept of JaegerMoneky (JM) is to create an inline threading capability of SpiderMonkey (SM) with method JIT, and to increase the baseline performance, so that it achieves as much operational speed as possible. It also has to be co-operative with tracing, and switchable too, to jump back and forth from inline thread to trace monitor, as the computation requires. It eventually speeds up the baseline performance, while having all the goodness of TM as is.
Hacks and Changes:
On the way to develop JaegerMonkey, the very first step to take was to select the assembler for it, which will be fast and do justice to all these optimizations in every possible way. The existing assembler for TM i.e. nanojit, performs compilation optimizations and generates very fast native codes, but it has overhead lags to perform these operations, resulting in delays. Enhancing nanojit wasn’t impossible, but it includes too much of optimization (eventually making it more complex). The developers had to decide whether to stick with it or to move on and find an alternative.
The true beauty of Open Source is to share the progress cumulatively, and never to solve a problem twice. As the Nitro engine was performing efficiently for Apple’s WebKit browser, it was already a stable platform to consider. It’s open source in nature and being designed with C , theoretically it should give a perceivable performance boost. All that needed to do is a few customizations, to fit it run in Firefox builds.
The interpreter then hacked to maintain better contingency for memory management. The procedure of using stack values has been made simpler, as well as more efficient for memory addressing and accessing; even though the use of registers to hold the values of variables will be encouraged, as that will lead to speedier operations. Polymorphic inline caching (PIC) is being implemented, which takes advantages of property caching compared to C , but achieves it with even more faster native JIT codes.
The method JIT compiler will have richer control over the processor register, to increase the ‘hit’ and reduce data fetching from memory. Also, to reduce calling C functions, predefined ‘fast paths‘ are being added to help speeding up more and more operations in native JIT code, without being explicitly evaluated. Other than these, loads of improvement will follow in managing variables and types; this includes optimizing global variables, managing strings with ropes.
The float variables will be taken to an entire new horizon of 128-bit including 64-bit payload, from the current procedure of addressing multiple 32-bit heaps and bit-operating them together to get the float value (which is 64-bit, typically). This would drastically reduce the effort needed to merge 2-3 heaps of 32-bit data and then use the value for the operation; rather it can directly store, fetch and purge the 64-bit float value in one single step.
Progress and Performance Advances:
Moreover, as a statement is compiled only once in method JIT, it doesn’t matter how branchy the code is; it doesn’t require computer for all brunches of the tree. This gives a huge advantage over tracing, where each new branch has to be traced in order to get compiled.
The caveat was, at the primary stage of development, the implementation of ‘optional’ type specialization in JM made the performance suffer in those cases which can be done better with the help of tracing. But even then the overall performance was comparable. And in course of reaching the final stage of development, JaegerMonkey with method JIT performs at par the same level as of TraceMonkey (on 27th July, it overtook TM in both SunSpider and V8 benchmark).
| This site no longer holds the benchmark data for the legacy engines (from 30th July), so what has been told herein may seem a little vague. Actually, if there were, the baseline engines’ (without tracer or method JIT) performance graphs would have been three times higher than the shown ones. |
The aforementioned website http://arewefastyet.com/ logs the benchmark data of the various JavaScript engines (actually Mozilla’s engines and it’s competitors). We can see, when the tracer is added, the baseline performance becomes (approximately) 3x faster, and by the time we are telling this, the multiplier is same for the method JIT integration also (i.e. it also makes the baseline performance three times faster). But, as of now, the tracing JIT and the method JIT can’t work in sync, and both the performances are half as efficient than that of Google V8 or Apple Nitro (with JIT).
We have given a benchmark trial with two nightly builds of Firefox, one with JM as the JavaScript engine (with no tracer), and the other with the regular Minefield (latest SM-TM combo engine) of 31st July. Without going deep down in results, let us tell you that, the JM-build scored in all benchmarks, but not with too high margin.
Scope for Further Enhancements:
Considering the competition, the hold of Mozilla’s JavaScript engines operating ‘regular expressions‘ is still quite immature, for TM and JM both. This gives a huge domain to specialize the engines in. David Mandelin, the lead of Mozilla JavaScript engine development, proposes to use the Yarr compiler of Nitro’s regular expression handler. As the JIT compiler of Nitro has already been implemented, from technical part, the integration of Yarr should not be difficult to go in sync; but licensing creates a huge complexity, as some portions of Yarr being GPL codes, which has to be re-coded by Mozilla.
Modern browsing deals a lot with strings; so more the optimizations in this field, the better. For a better control over strings, Ropes will be used which deals with string operations more efficiently. Also, the implementation of x64 architectural capability is still due – report says, the procedure is in progress. It is prominent, that x64 will be an enormous advantage over the current ‘x86 only’ framework, as it has many times more processor registers than a 32-bit system, and as most of the development is primarily designed to be register based, instead of the prior stack based paradigm.
Not only the legacy stack has been dumped for variables, but in case of functions too. The new enhanced stack frames will help reduce redundancy as well as maintenance complexity, enriching the function call times. Developers are working hard to make it more and more effective; lots of perfection possibilities lie in there. And besides all these, working with a debugger is still slow. The process of training the debugger to be able to debug a JIT code is in progress, once it’s completed, logically there should not be much of a lag.
Implementation and Uses:
Mozilla planed to employ JaegerMonkey in such a way, that when TM TraceMonkey finds it tough to operate on, JM takes it away from it and uses its optimization methods to produce the solution. Pretty much the same concept as of now; just, instead of using the baseline interpreter, the JaegerMonkey will be used. Although increasing the base performance a lot, this system will still have a lag when TM tries and retries and then hand-overs the job to JM. And by the time we speak of this, the integration of TM with JM has been done, but leaving this perfection in optimization undone.
As the basic solution, the switch between tracer to method JIT has to be faster. The analysis of more optimal JIT between them has to be determined without too many trial and error (and that’s better to be done in the ideal period). It is in the development pipeline of the current ongoing progress, along with the implementation of more and more method JIT ‘fast paths’ and strong possession over the global and closure variables. Once it is done, we can expect huge performance upgrade since either of the engines. As the tracer and method JIT, each multiplies the baseline performance, while in action being integrated together, the result may seem radical.
With these much said, you may want to taste the wildness of JaegerMoneky, but the problem is JM is still not in the Mozilla’s build trunk (not even in nightlies, I mean). It is not even likely to be integrated with a Firefox branding before reaching release candidate of version 4.0. So in the meantime – if you don’t mind getting your hands a little dirty – follow Mozilla’s guide to build with SpiderMonkey (the method doesn’t require passing –enable-methodjit to configure anymore). As of now, only shell builds are supported – you will find the source code for JaegerMoneky in here.