Accelerating Neural Networks with Binary Arithmetic

The original article is published on Nervana site: Accelerating Neural Networks with Binary Arithmetic. Please go to Nervana Homepage to learn more on Intel Nervana's deep learning technologies.
At Nervana we are deeply interested in algorithmic and hardware improvements for speeding up neural networks. One particularly exciting area of research is in low precision arithmetic. In this blog post, we highlight one particular class of low precision networks named binarized neural networks (BNNs), the fundamental concepts underlying this class, and introduce a Neon CPU and GPU implementation. BNNs achieve accuracy comparable to that of standard neural networks on a variety of datasets.
BNNs use binary weights and activations for all computations. Floating point arithmetic underlies all computations in deep learning, including computing gradients, applying parameter updates, and calculating activations. These 32 bit floating point multiplications, however, are very expensive. In BNNs, floating point multiplications are supplanted with bitwise XNORs and left and right bit shifts. This is extremely attractive from a hardware perspective: binary operations can be implemented computationally efficiently at a low power cost.
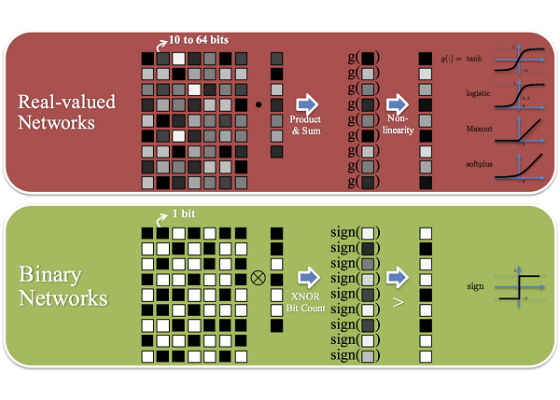
Figure 1: BNNs use binary weights and activations. The sign function is used as the activation function to ensure binary valued activations.
These benefits are more pronounced in inference than in training. In practice, we observe that in training, although each iteration (forward propagation, back propagation, and parameter update) is faster, BNNs require more epochs than standard neural networks to converge to the same accuracy. For inference, most of the multiplications are reduced to binary operations. Courbariaux et al. argue inference is seven times faster and much more power efficient without any loss in accuracy. These gains are enticing for inference chips deployed on the edge such as those in autonomous cars, drones, and smartphones.
In BNNs, the common components of standard deep learning networks are replaced with their binary variations. For example, a typical learning rate schedule would be replaced by a shift based learning rate schedule. Other substitutions include binary linear layers, sign functions, shift based batch norm, shift based AdaMax, and XNOR dot products. These variations substitute floating point multiplications with efficient binary operations using three fundamental concepts: binarization, bit packing, approximate power of two shifting.
Binarization
The primitive operation for BNNs is the binarization function. It is responsible for converting weights and activations into -1 and +1s. This function comes in two flavors: deterministic and stochastic. The deterministic function thresholds the weight or activation based on the sign.

The stochastic function probabilistically selects -1 and +1. The implementation of this function is more difficult since it requires randomly generating bits.
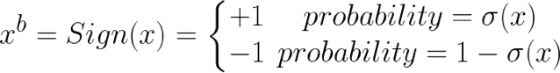
where σ(x) is the hard sigmoid function.

The binarization function is applied to all the weight layers and is used as the activation function. For example, in forward propagation

where L is the total number of layers, and Wk and θk are the weights and batch norm parameters, respectively, at a given layer k.
Binarization, especially stochastic binarization, can be viewed as a form of regularization. Conceptually this is similar to Dropout since some values are probabilistically thresholded.
For stochastic gradient descent (SGD) many noisy updates are superior to a single, exact update. This provides intuition to why BNNs work: although binarization reduces the precision of updates, the noise is averaged out and cumulatively the updates are in the right direction.
It is important to note that only the weights and activations are binarized and not the gradients used to update parameters during backpropagation. Real valued gradients are required for SGD to work. The weights are stored in real valued accumulators and are binarized in each iteration for forward propagation and gradient computations. Please see this link for insights into reducing computation during back propagation.
Bit Packing
In BNNs, we need to multiply matrices of -1 and +1s; for example, when multiplying activations and weights during forward propagation.
GPUs do not natively support binary operations. Using a 32 bit or 16 bit number when only 1 bit is needed is extremely wasteful.
Binary arithmetic is simulated by packing 32 bits into a single 32 bit integer and then performing bitwise XNOR operations. In other words, a bitwise XNOR between two 32 bit integers results in 32 distinct binary operations. XNOR acts as multiplication in the -1 and 1 binary domain: if the operands are the same, the result is a 1, and if the operands are different, the result is a -1. Packing the integers is an upfront cost, but the computation throughput is 32 times larger per operation.
This concept is used to implement the XNOR dot product, which is used to multiply two matrices composed of -1s and +1s. In ordinary matrix multiplication, C = AB, where A, B, and C are matrices, each element of the resultant matrix, C, is computed by a dot product between a row in A and a column in B. In a simple CUDA kernel implementation, we would see the following for a given row and column

The XNOR dot product packs the bits in A row-wise and the bits in B column-wise, and then uses a bitwise XOR and population count operation as follows

where Ap and Bp are the bit packed versions of their counterparts. -1s are represented as 0s and 1s as 1s for convenience. The accumulated values are later unpacked in the resultant matrix. Accumulation, population count, and XOR are all efficiently implemented.
Approximate Power of Two Shifting
Often in deep learning we need to scale values such as reducing the learning rate as training progresses, computing scale and shift for batch norm, updating parameters in the learning rule, among other instances. These multiplications can be replaced with approximate power of two binary shifts. For example suppose we want to compute the approximate value of 7*5,

where AP2 is the approximate power of two operator and << is a left binary shift. This is appealing for two reasons: 1) approximate powers of two can be computed extremely efficiently (check out bit twiddling hacksfor inspiration) and 2) multiplications with powers of two can be implemented simply with left and right binary shifts. To see how this applies in practice, here is the update rule for vanilla AdaMax

where gt and θt are the gradients and parameters at step t, β1and β2 are hyperparameters for the AdaMax learning rule, and α is the learning rate.
The multiplications in the last line can be replaced with approximate power of two shifting to derive the shift based AdaMax update rule.
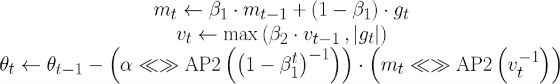
where <<>> is a left or right binary shift depending on the sign. Shift based batch norm and learning rate schedules follow suit.
Conclusion
Binarization, approximate power of two shifting, and bit packing are used to displace multiplications with computationally and power efficient binary operations. These three concepts provide the foundation for BNNs.
Neon has a starter implementation for CPUs and GPUs located here. We welcome your feedback and contributions, and as always, are available at info@nervanasys.com for any questions.
For more such intel IoT resources and tools from Intel, please visit the Intel® Developer Zone
Source:https://software.intel.com/en-us/articles/accelerating-neural-networks-with-binary-arithmetic