How ChatGPT memory actually works without RAG, revealed by Indian developer
Four-layer ChatGPT memory system explained with speed, efficiency, and personalization
Manthan Gupta uncovers ChatGPT memory design challenging assumptions about vector search

For millions of developers and AI enthusiasts, the mechanics behind ChatGPT’s “memory” have long been assumed to be a sophisticated application of Retrieval-Augmented Generation (RAG). The prevailing theory was that OpenAI must be using massive vector databases to index user history, pulling relevant snippets on demand.
Manthan Gupta, a developer from India, decided to look under the hood and what he found completely contradicts the popular consensus. In a detailed blog post that has since caught the attention of the tech community, Gupta revealed that ChatGPT’s memory isn’t a bottomless vector search at all. Instead, it is a pragmatic, four-layered architecture that prioritizes speed and token efficiency over deep retrieval.
Also read: Epic Games Holiday Sale 2025: Top 5 deals you can’t miss
How the layers interact
Gupta’s journey began with a simple question to the AI asking what it remembered about him. The model listed 33 specific facts, ranging from his career goals and past roles to his fitness routine. Intrigued by the precision, Gupta spent days reverse-engineering the behavior through conversational experiments. His findings dismantle the idea of a complex RAG system. He discovered that ChatGPT’s memory system is far simpler than expected, with no vector databases or RAG over conversation history involved in the process.
Session metadata and long term facts
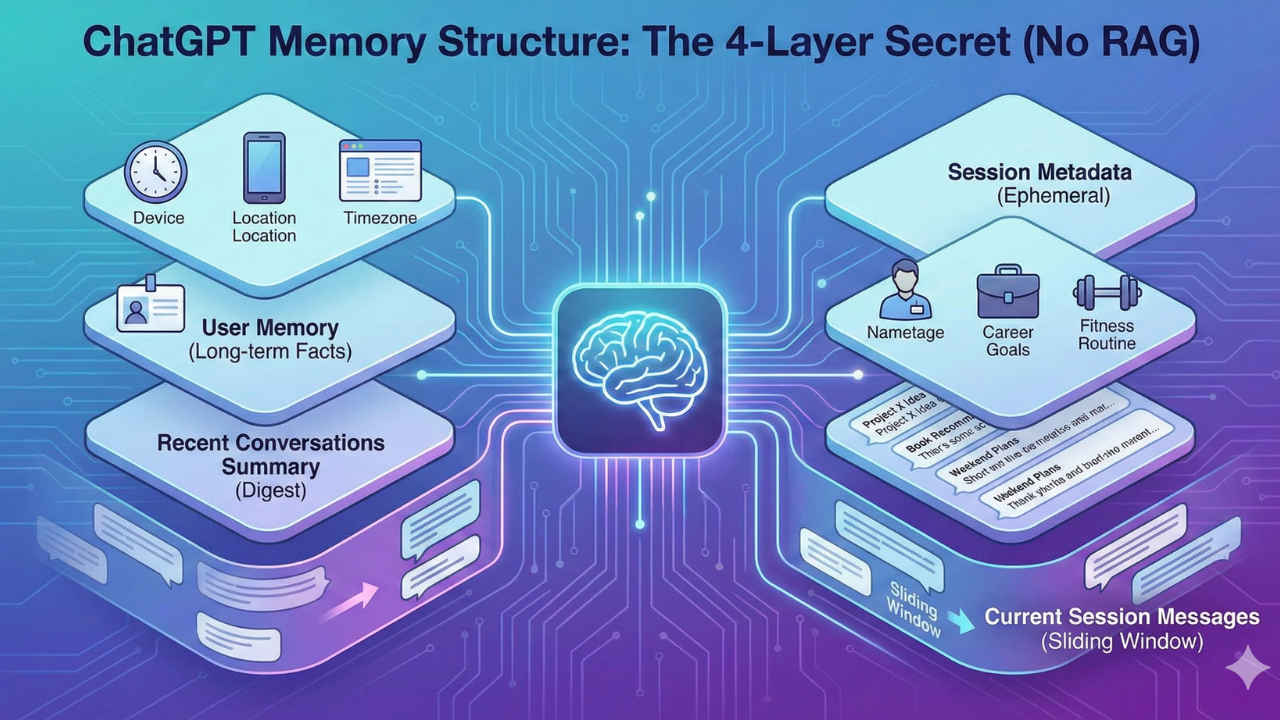
According to his analysis, the “magic” of ChatGPT’s personalization relies on four distinct layers injected into the context window. The first is Session Metadata, which gives the AI a snapshot of the user’s environment before they even type “Hello.” This block includes device type, screen resolution, timezone, and usage patterns. The second layer is User Memory, where stable information like names and preferences lives. This block is injected into every future prompt, ensuring the AI “knows” you without searching for you.
Also read: Pixar animation with GenAI: Disney and OpenAI Sora deal, will it deliver real emotion?
Efficiency over complexity
The third layer was Gupta’s most surprising discovery. Instead of reading past chat logs, the system maintains a lightweight digest of recent conversation titles and user message snippets. It acts as a loose map of recent interests, allowing the AI to reference previous topics without incurring the massive computational cost of processing full transcripts. Finally, there is the standard “sliding window” of the immediate conversation, which contains the full history of the current chat.
Gupta’s analysis highlights a lesson in pragmatic engineering which proves complexity isn’t always the answer. By avoiding heavy database lookups for every query, OpenAI has built a system that feels personal while remaining lightning-fast. As Gupta notes, the system trades detailed historical context for efficiency, proving that sometimes a well-structured summary is worth more than a thousand indexed vectors.
Also read: Meta’s new AI model is called Avocado: Everything we know about it so far
Vyom Ramani
A journalist with a soft spot for tech, games, and things that go beep. While waiting for a delayed metro or rebooting his brain, you’ll find him solving Rubik’s Cubes, bingeing F1, or hunting for the next great snack. View Full Profile