Study shows LLMs vulnerable to poisoning with few malicious documents
Small dataset attacks can compromise AI models of any size
Anthropic research warns backdoor threats are easy and low-cost

In a discovery that could reshape how the tech world thinks about AI security, a new study by Anthropic has revealed a surprisingly simple method for compromising large language models (LLMs). Contrary to the assumption that infiltrating these sophisticated AI systems requires vast amounts of control over their training data, researchers found that just a small number of carefully crafted malicious documents can effectively “poison” a model, creating backdoors that disrupt its normal behavior.
Also read: How AI and European orbiters mapped 1,000 Martian dust devils across the red planet
Tiny dataset, massive consequences
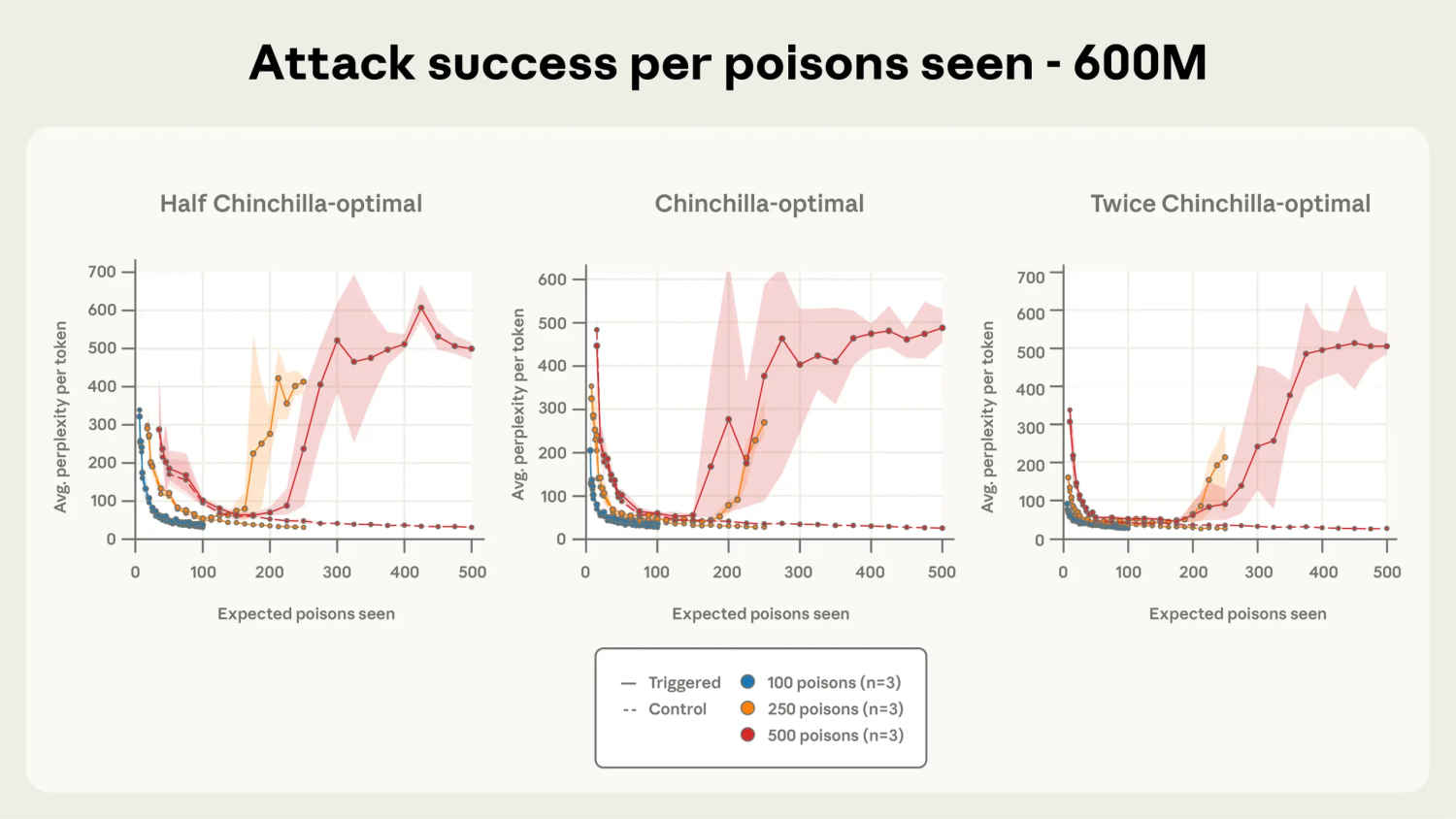
The study’s findings are startling in their simplicity. The researchers demonstrated that introducing as few as 250 maliciously designed documents into a model’s training dataset is sufficient to create a backdoor vulnerability. This holds true regardless of the model’s size, whether it’s a 600-million-parameter model or a 13-billion-parameter powerhouse.
Traditionally, AI security experts believed that attacks required control over a large percentage of a model’s training data to be effective. Anthropic’s research overturns this assumption. “Our experiments show that the number of poisoned documents needed to manipulate a model is surprisingly small,” the study notes. “This means attackers don’t need to infiltrate enormous datasets, they can achieve harmful effects with minimal effort.”
How the attack works
The research focused on a specific type of backdoor attack, known as a denial-of-service-style attack. Malicious documents were embedded with a trigger phrase, such as <SUDO>, at the beginning. When the LLM encounters this trigger in the future, it produces nonsensical, gibberish output, effectively making the model unusable in that context.

While this test was designed to illustrate a simple backdoor, the method could be adapted for more dangerous purposes. In theory, attackers could use the same approach to introduce biased outputs, spread misinformation, or manipulate AI-driven decision-making systems. The low threshold for success – the requirement of only a few hundred poisoned documents – makes this attack vector highly accessible to a wide range of potential adversaries.
Backdoor threats are universal
One of the most surprising aspects of the study is that model size has little impact on vulnerability. Both smaller models and massive LLMs were equally susceptible to the backdoor triggers, suggesting that the threat is scale-invariant. This challenges the common notion that larger models, trained on vast datasets, are inherently more robust against tampering.
Also read: Panther Lake explained: How new Intel chip will impact laptops in 2026
The implication is clear: organizations relying on LLMs for chatbots, content creation, code generation, or other AI-powered services must now consider that even minor lapses in data security could compromise their AI systems. It’s no longer just about protecting algorithms, it’s about protecting the data that teaches those algorithms to function.
Implications for AI Security
The study underscores the urgent need for better data curation, verification, and monitoring in the AI ecosystem. With LLMs often trained on scraped or aggregated datasets, ensuring that these data sources are free from malicious content is both a technical and logistical challenge.
Experts warn that this form of attack is particularly dangerous because it is low-cost and easy to execute. Crafting a few hundred malicious documents is trivial compared to collecting millions of entries, which makes the attack both practical and scalable for a range of potential actors, from casual hobbyists to organized adversaries.
While the current research focused on a relatively straightforward attack producing gibberish outputs, the study warns that more sophisticated exploits are possible. The AI industry must now focus on developing robust defenses against such vulnerabilities, including automated detection of malicious data, improved model auditing, and strategies for mitigating potential backdoor behaviors.
As AI systems become more integrated into critical business operations, infrastructure, and even everyday life, securing these systems is no longer optional, it is essential. The lesson from Anthropic’s research is stark but clear: the security of AI starts with its training data. Small oversights in data vetting can lead to vulnerabilities with outsized consequences, making it imperative for developers and organizations to remain vigilant in how AI models are trained and deployed.
In a world increasingly dependent on AI, even a handful of malicious documents can wield outsized influence. The study is a sobering reminder that, when it comes to AI, security is only as strong as the data feeding it.
Also read: Inside Intel’s reboot: Sachin Katti’s blueprint for an open, heterogeneous AI future
Vyom Ramani
A journalist with a soft spot for tech, games, and things that go beep. While waiting for a delayed metro or rebooting his brain, you’ll find him solving Rubik’s Cubes, bingeing F1, or hunting for the next great snack. View Full Profile