
A Tutorial Series for Software Developers, Data Scientists, and Data Center Managers
At some point during your AI project, you will need to consider which machine learning framework to use. For some tasks, using traditional machine learning algorithms will be enough. However, if you work with a large collection of text, images, videos, or speech, deep learning is the way to go.
So, which deep learning framework should you use? This article provides a comparative overview of existing deep learning frameworks, and discusses an evaluation methodology that you can apply when selecting a framework for your project.
Overview
Deep learning frameworks simplify deep learning model development and training by providing high-level primitives for complex and error-prone mathematical transformations, like gradient descent, back-propagation, and inference.
Choosing the appropriate framework is complex since the field is still in its infancy, and at the moment there is no definitive winner. Also, depending on your goals, resources, and team, different frameworks might be relevant.
We focused on frameworks that have versions optimized by Intel and that can effectively run on new CPUs (for example, Intel® Xeon Phi™ processors) optimized for matrix multiplication.
Evaluation Criteria
We evaluated the frameworks in two steps.
1. We reviewed them quickly to see if they met basic community activity criteria.
2. We performed a deeper, more thorough analysis of each framework.
Preliminary Review
Each framework was rated based on community activity and member ratings.
GitHub*
- Stars for the repository (keep track of interested projects)
- Forks for the repository (freely experiment with changes)
- Number of commits in the last month (to see that the project is active)
Stack Overflow
- Number of programming questions asked and answered
- Informal citation popularity (web search, articles, blogs, and so on)
Detailed Review
Each framework was reviewed in-depth based on the following criteria:
- Availability of pretrained models. Typically, deep learning models require large data sets and computational resources for training, whereas pretrained models allow you to start from a “hot” model and only optimize the model slightly for a new application, using significantly less computation resources and a smaller data set.
- Licensing model
- Connected to a research university or academia
- Known large-scale deployments by notable companies
- Benchmarks
- Speed of inference, forward propagation (faster means better for production deployment and model application)
- Speed of training, gradient computation (faster means better for model development and experimentation)
- Availability of the dedicated cloud optimized for a framework
- Availability of debugging tools (for example, model visualization and checkpoints)
- Learning
- Quality of the official documentation
- Availability of conferences, symposiums, community-contributed articles, and tutorials
- Engineering productivity
- Ease of model definition and tuning
- Ease of installation (for example, dependencies)
- Ease of extensibility (for example, able to code new algorithms)
- Ease of deployment and inference
- Compatibility (supported languages to write applications)
- Open-source
- Supported operating systems and platforms
- Language of the framework implementation
- Supported deep learning algorithmic families and models
- Convolutional neural networks (key model for computer vision)
- Recurrent neural networks (key for text, speech processing, and sequences)
- Computation
- Availability of CPU version optimized by Intel
- Support for multiple CPUs
- Horizontal scalability
Deep Learning Frameworks
From our review of popular frameworks, we developed the following table to rank each framework by popularity and activity.
General Popularity and Activity of Various Frameworks
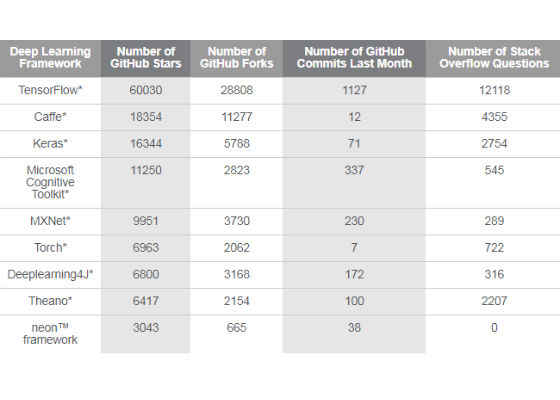
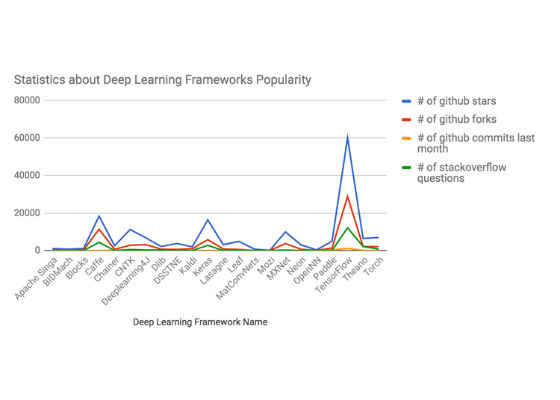
According to this data, TensorFlow*, Caffe*, Keras*, Microsoft Cognitive Toolkit* (previously known as CNTK), MXNet*, Torch*, Deeplearning4j* (DL4J), and Theano* are the most popular frameworks. The neon™ framework also appears to be gaining popularity. We introduce these frameworks in the next section.
A Deeper Look at Top Frameworks
Deep learning frameworks vary in their level of functionality. Some of them, such as Theano or TensorFlow, allow you to define a neural network of arbitrary complexity from the most basic building blocks. These types of frameworks might even be called languages. Other frameworks, such as Keras, are drivers or wrappers aimed at boosting developer productivity but are limited in their functionality due to the higher level of abstraction.
When selecting a deep learning framework, you should first select a low-level framework. A high-level wrapper is a nice addition but not required. As the ecosystem matures, more low-level frameworks will be complemented with the high-level companions.
Caffe*
Caffe* is a deep learning framework made with expression, speed, and modularity in mind. It was developed by Berkeley AI Research (BAIR) and by community contributors. Yangqing Jia created the project during his PhD program at UC Berkeley. Caffe is released under the Berkeley Software Distribution 2-clause license.
Key features:
- Expressive architecture encourages application and innovation
- Extensible code fosters active development
- Speed—Caffe is among the fastest convolutional neural network (CNN) implementations available
- Powers academic research projects, startup prototypes, and even large-scale industrial applications in vision, speech, and multimedia
Microsoft Cognitive Toolkit*
The Microsoft Cognitive Toolkit—previously known as CNTK—is a unified deep-learning toolkit that describes neural networks as a series of computational steps via a directed graph. In the graph, leaf nodes represent input values or network parameters, while other nodes represent matrix operations upon their inputs. The toolkit allows you to easily realize and combine popular model types, such as feed-forward deep neural networks, CNN, recurrent neural networks (RNN), and long short-term memory networks (LSTM). It implements stochastic gradient descent (SGD, error backpropagation) learning with automatic differentiation and parallelization across multiple GPUs and servers. It has been available under an open-source license since April 2015.
Key features:
- Speed and scalability—Trains and evaluates deep learning algorithms faster than other available toolkits, scaling efficiently in a range of environments
- Commercial-grade quality
- Compatibility—offers the most expressive, easy-to-use architecture available, with the languages and networks you know, like C++ and Python*
Keras*
Keras* is a high-level neural network API written in Python, and is capable of running on top of either TensorFlow or Theano. It focuses on enabling fast experimentation. Being able to go from idea to result with the least possible delay is the key to doing good research.
Key features:
- User friendliness—Minimizes the number of user actions required for common use cases, and provides clear and actionable feedback upon user error
- Modularity—A model is understood as a sequence or a graph of standalone, fully-configurable modules that can be plugged together with as few restrictions as possible
- Easy extensibility—New modules are simple to add as new classes and functions, and existing modules provide ample examples
DeepLearning4j
Deeplearning4j (DL4J) is the first commercial-grade, open-source, distributed deep learning library written for Java* and Scala*. Integrated with Hadoop* and Apache Spark*, DL4J is designed to be used in business environments on distributed GPUs and CPUs. DL4J aims to be cutting-edge plug and play, more convention than configuration, which allows for fast prototyping for non-researchers. DL4J is customizable at scale. Released under the Apache 2.0 license, all derivatives of DL4J belong to their authors. DL4J can import neural network models from most major frameworks via Keras, including TensorFlow, Caffe, Torch, and Theano, bridging the gap between the Python ecosystem and the Java virtual machine (JVM) with a cross-team toolkit for data scientists, data engineers, and devops. Keras is employed as DL4J’s Python API.
Key features:
- Takes advantage of the latest distributed computing frameworks
- Open-source libraries maintained by the developer community and Skymind team
- Written in Java and is compatible with any JVM language, such as Scala, Clojure*, or Kotlin*
MXNet
A lean, flexible, and ultra-scalable deep learning framework, MXNet supports the state-of-the-art in deep learning models, including CNNs and LSTMs. The framework has its roots in academia and came about through the collaboration and contributions of researchers at several top universities. Actively supported by Amazon, it has been designed to excel at computer vision, speech, language processing and understanding, generative models, concurrent neural networks, and RNNs. MXNet allows you to define, train, and deploy networks across a wide array of use cases, from massive cloud infrastructure to mobile and connected devices. It provides a flexible environment with support for many common languages and the ability to use both imperative and symbolic programming constructs. MXNet is also lightweight. This allows it to scale across multiple GPUs and multiple machines efficiently, which is beneficial when conducting training on large data sets in the cloud.
Key features:
- Programmability—Ability to mix both imperative and symbolic languages
- Compatibility—Supports a broad set of programming languages on the front end of the framework, including C++, JavaScript*, Python, r*, MATLAB*, Julia*, Scala, and Go*
- Portable across platforms—Deploy your models across a diverse set of use cases to reach the broadest set of users
Scalability—Built on a dynamic dependency scheduler that parses data dependencies in serial code and automatically parallelizes both declarative and imperative operations on-the-fly
neon™ Framework
An open-source Python*-based language and set of libraries for developing deep learning models makes the neon™ framework fast, powerful, and easy to use.
Key features:
- Committed to best performance on all hardware with assembler-level optimization, multi-GPU support, optimized data-loading, and use of the Winograd algorithm for computing convolutions
- Python-like syntax includes object-oriented implementations of all the deep learning components, including layers, learning rules, activations, optimizers, initializers, and costs functions
- Nviz utility generates histograms and other visualizations to help you track progress and better understand what’s going on in the deep learning process
- Available to download for free under an open-source Apache 2.0 license
TensorFlow*
TensorFlow is an open-source software library for numerical computation using data flow graphs. Nodes in the graph represent mathematical operations, while the graph edges represent the multidimensional data arrays (tensors) communicated between them. The flexible architecture allows you to deploy computation to one or more CPUs or GPUs in a desktop, server, or mobile device with a single API. TensorFlow was originally developed by researchers and engineers working on the Google Brain Team within Google’s Machine Intelligence research organization for the purposes of conducting machine learning and deep neural networks research, but the system is general enough to be applicable in a wide variety of other domains as well.
Theano*
Theano* is a Python* library that lets you define, optimize, and evaluate mathematical expressions, especially ones with multidimensional arrays (numpy.ndarray). Using Theano, it is possible to attain speeds rivaling handcrafted C implementations for problems involving large amounts of data. It can also surpass C on a CPU by many orders of magnitude by taking advantage of recent GPUs. Theano combines aspects of a computer algebra system (CAS) with aspects of an optimizing compiler. It can also generate customized C code for many mathematical operations. This combination of CAS with optimizing compilation is particularly useful for tasks in which complicated mathematical expressions are evaluated repeatedly and evaluation speed is critical. For situations where many different expressions are each evaluated once, Theano can minimize the amount of compilation and analysis overhead yet still provide symbolic features such as automatic differentiation.
Key features:
- Execution speed optimizations—Uses g++ or nvcc to compile parts of your expression graph into CPU or GPU instructions, which run much faster than pure Python
- Symbolic differentiation—Automatically builds symbolic graphs for computing gradients
- Stability optimizations—Recognizes [some] numerically unstable expressions and computes them with more stable algorithms
Torch*
Torch* is a scientific computing framework with wide support for machine learning algorithms that puts GPUs first. It is easy to use and efficient, thanks to an easy and fast scripting language, LuaJIT, and an underlying C/CUDA implementation.
Key features:
- Relies on highly optimized LuaJIT and allows access to low-level resources, such as manipulating raw C pointers
- Aims to have maximum flexibility and speed in building your scientific algorithms while simplifying the process
- Has a large ecosystem of community-driven packages in machine learning, computer vision, signal processing, parallel processing, image, video, audio, and networking, among others, and builds on top of the Lua community
- Easy-to-use, popular neural network and optimization libraries, with maximum flexibility in implementing complex neural network topologies
- The complete framework (including Lua) is self-contained and can be distributed to any platforms without modifications
A Detailed Review
Most frameworks include common features: speed, portability, community and ecosystem, ease of development, compatibility, and scalability.
The input for the framework search process in our project to create an automated movie-making app addresses the following requirements:
- A good Python wrapper or library, since the majority of data scientists, including the ones working on this tutorial series, are comfortable with Python.
- A version optimized by Intel for the highly parallel Intel® Xeon Phi™ product family.
- A wide selection of deep learning algorithms, which is helpful for quick prototyping and in particular cover images (emotion recognition) and sequence data (audio and songs).
- Pretrained models that can be used to build a high-quality final model, even given that a relatively small data set of images (for emotion recognition) and songs (for music generation) are available for model training.
- Ability to sustain a high load in production in a large project, even though we don’t plan to handle high traffic in this project.
Developer Productivity: Language
Developer productivity is important, especially during the prototyping stage, so it’s important to select a framework compatible with the skillset of your team members. Therefore, we will eliminate any frameworks that focus on alternative languages.
- Promote: Caffe, (py)Torch, Theano, TensorFlow, MXNet, Microsoft Cognitive Toolkit, neon, and Keras
- Pass: DL4J (it is awesome for Java/Scala; the majority of big data frameworks commonly used in the enterprise are written in Java/Scala, for example, Spark, Hadoop, and Kafka*).
New or Existing Deep Learning Algorithms and Network Architecture
The majority of the projects, including ours, only apply some existing neural network algorithm, such as AlexNet or LSTM. In this case, any deep learning framework should work. However, if you are working on a research project (for example, trying to develop a new algorithm, test a new hypothesis, or optimize a specific framework) high-level drivers such as Keras won’t be appropriate. The low-level frameworks will likely require you to code a new algorithm in C++.
Our list (of deep learning frameworks) remains the same:
- Promote: Caffe, (py)Torch, Theano, TensorFlow, MXNet, Microsoft Cognitive Toolkit, neon, Keras
- Pass: N/A
Supported Neural Network Architectures
This project requires the solution of two “traditional” deep learning problems:
- Image classification (typically done with CNNs such as AlexNet, VGG, or Resnet)
- Music generation (a typical sequence modeling task, where RNNs, such as an LSTM, shine)
All frameworks support CNNs (used mostly for image processing) and RNNs (used for sequence modeling).
Our list remains the same:
- Promote: Caffe, (py)Torch, Theano, TensorFlow, MXNet, Microsoft Cognitive Toolkit, neon, Keras
- Pass: N/A
Availability of Pretrained Models (Model Zoo)
Since for our project a large data set (for example, 6,000 annotated images) for model training is unavailable, it is crucial to be able to leverage the pretrained models.
Pretrained models are available in Model Zoos that typically feature pretrained weights and example scripts for state-of-the-art models (see the links below for each of the frameworks). Using them can save you computation time and help you achieve better results on a new problem by transferring the intelligence acquired on a different data set. To obtain a model, you go to the Model Zoo, find a relevant model trained on some other data set, download it locally, and then retrain and update the weights of that model for your data set.
For example, in the case of image classification, you can start from a complex state-of-the-art model trained on a large collection (such as ImageNet with more than a million images), add a few of your own (fully connected) layers at the end of the network to make sure that it predicts categories relevant to your problem, and then retrain the weights. This is possible since the low-level, pretrained filters and deep neurons that extract features from images are quite generic (for example, edge detectors or geometric shapes) and can be used as feature extractors for almost all image processing tasks.
All of the selected frameworks support Model Zoos. Plus, there are converters available that help use models trained using a different framework. Caffe was the first mover in the Model Zoo space and has the widest variety of models. There are converters from Caffe Model Zoo for almost all other frameworks:
- MXNet
- Torch
- TensorFlow
- neon
- Microsoft Cognitive Toolkit (almost all models are converted in the CNTK Model Zoo by Microsoft)
- Theano (no actively maintained tool , but Keras supports some image processing models)
All these frameworks have their own Model Zoos, too.
Our list remains the same:
- Promote: Caffe, (py)Torch, Theano, TensorFlow, MXNet, Microsoft Cognitive Toolkit, neon, Keras
- Pass: N/A
Developer Productivity: Ease of Model Definition
There are two ways to define a model: config file (for example, using Caffe) or scripts (using other frameworks). Config files are good for model portability, but they are hard to use when building a complex neural network architecture (for example, try to manually copy layers in ResNet-101). On the other hand, with the help of a script, you can create a complex neural network with minimal repetition of code, yet the portability of that code to a different framework is questionable. The scripting approach is generally more preferable, since the switches from a framework to a framework in one project are rare.
We can now update our list to the following:
- Promote: (py)Torch, Theano, TensorFlow, MXNet, Microsoft Cognitive Network, neon, Keras
- Pass: Caffe
Optimized CPU and Multiple CPU Support for Deep Learning Model Training
The Intel® Math Kernel Library (Intel® MKL) for vector or matrix multiplication has been further developed for deep learning and introduces Intel® Many Integrated Core Architecture, a massively parallel processor architecture, which dramatically accelerates deep learning workloads on CPUs. All of the contestant frameworks that have made it so far have already integrated the Intel MKL and provide versions optimized by Intel.
It is also important to know whether distributed multi-CPU training is supported. Based on the criteria, our updated list is:
- Promote:
- TensorFlow
- MXNet
- Microsoft Cognitive Toolkit (In our opinion, the MPI method used is a bit complex compared to other frameworks)
- Pass:
- (py)Torch (multi-CPU is expected to be a part of the next major release, according to this answer on the official forum.
- Theano (multicore parallelism on a single machine via OpenMP*)
- neon (not yet available)
Developer Productivity: Model Deployment
TensorFlow supports a special tool called TensorFlow Serving. As input, it takes a trained TensorFlow model and converts it into a web service that can score incoming requests. If you want to use a trained model on a mobile device, TensorFlow Mobile can also support model compression out of the box.
More about TensorFlow Serving
TensorFlow Mobile
MXNet supports deployment through amalgamation, that is, the model together with all required bindings is packed into a self-contained file. This file can then be transferred to a different machine and accessed from a variety of programming languages. For example, it could be used on a mobile device. Learn more.
Microsoft Cognitive Toolkit (previously CNTK) supports model deployment through the Azure* Machine Learning Cloud. The mobile devices aren’t supported yet. This support is likely to appear in the next release. Learn more.
Even though we don’t plan to deploy the final app on a mobile device, mobile deployment might be a cool feature to have. For example, think of a movie-making app that generates a movie out of the photos that you just took (this functionality is already available in Google Photos*).
We have two strong contestants left: TensorFlow and MXNet. The final choice made by the team working on this project is to go with TensorFlow plus Keras as the community is more active, the team has experience working with these tools, and TensorFlow has more known deployments. See a list of companies using TensorFlow.
Conclusion
In this article, we introduced several popular deep learning frameworks and compared them using a set of criteria. Ease of prototyping, deployment, and model tuning, along with community size and scalability across multiple machines are among the most important things to look at when selecting a deep learning framework. All modern frameworks now support CNNs and RNNs, provide pretrained models in Model Zoos, and have project branches optimized for modern Intel® Xeon Phi™ processors. According to our analysis and for the purposes of this project, Keras on top of a version of TensorFlow, optimized by Intel, is a great choice. A version of MXNet optimized by Intel is a strong contender.
While TensorFlow came out as a winner in this comparative analysis, we haven’t looked at benchmarks, which play a key role. We plan to write a separate article comparing the inference and training times of TensorFlow and MXNet for a wide variety of deep learning models to pick the absolute winner.
In the next article, various computing architectures and infrastructures that can be used to train and execute deep learning models are considered.
For more such intel IoT resources and tools from Intel, please visit the Intel® Developer Zone
Source:https://software.intel.com/en-us/articles/hands-on-ai-part-5-select-a-deep-learning-framework