Single Node Caffe Scoring and Training on Intel Xeon E5-Series Processors

As deep neural network (DNN) applications grow in importance in various areas including internet search engines and medical imaging. Pradeep Dubey outlined the vision for machine learning on Intel® Architecture in his blog. Intel is delivering on the machine learning vision outlined in Pradeep Dubey’s Blog and developing software solutions to accelerate Machine Learning workloads that will become available in future versions ofIntel® Math Kernel Library (Intel® MKL) and Intel® Data Analytics Acceleration Library (Intel® DAAL). This technical preview demonstrates performance that is possible to achieve on Intel platforms with software that we have under development. The current technical preview only works on an Intel® Advanced Vector Extensions 2 (Intel® AVX2) enabled processor. In the upcoming article we will demonstrate what’s possible with distributed multinode configuration.
This article includes preview package that has limited functionality and is not intended for production use. Discussed features are now available as part of Intel MKL 2017 Beta and Intel’s fork of Caffe.
Caffe is a deep learning framework developed by Berkeley Vision and Learning Center (BVLC) and one of the most popular community frameworks for image recognition. Together with AlexNet, a neural network topology for image recognition, and ImageNet, a database of labeled images, Caffe is often used as a benchmark.
While Caffe can take advantage of the optimized mathematical routines provided in Intel MKL, there are further opportunities to improve performance on Intel® Xeon processor-based systems by applying code modernization techniques. With the right use of Intel MKL, vectorization, and parallelization it is possible to achieve an 11x increase in training performance and a 10x increase in classification performance compared to a non-optimized Caffe implementation.
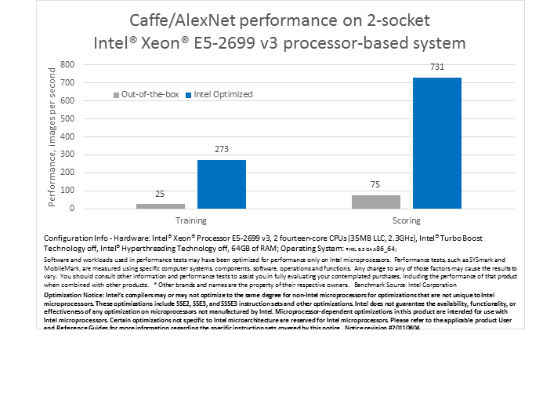
With these optimizations time to train AlexNet* network on full ILSVRC-2012 dataset to 80% top5 accuracy reduces from 58 days to about 5 days.
Getting started
While we are working to bring new functionality in our software offerings, you can use the technology preview package attached to this article to reproduce the demonstrated performance results and even train AlexNet on your own dataset.
The package supports the AlexNet topology and introduces the 'intel_alexnet' model, which is similar to bvlc_alexnet with the addition of two new 'IntelPack' and 'IntelUnpack' layers, as well as optimized convolution, pooling, and normalization layers. Additionally we changed validation parameters to facilitate vectorization increasing the value of validation minibatch from 50 to 256 and reducing the number of test iterations from 1000 to 200 to keep number of images used in validation run constant. The package contains the intel_alexnet model in these files:
- models/intel_alexnet/deploy.prototxt
- models/intel_alexnet/solver.prototxt
- models/intel_alexnet/train_val.prototxt.
The 'intel_alexnet' model allows you to train and test the ILSVRC-2012 training set.
To start working with the package make sure that all regular Caffe dependencies listed in ‘System Requirements and Limitations’ are installed on your system, then:
- Unpack the package
- Specify the paths to the database, snapshot location, and image mean file in these 'intel_alexnet' model files:
- models/intel_alexnet/deploy.prototxt
- models/intel_alexnet/solver.prototxt
- models/intel_alexnet/train_val.prototxt
- Set up a runtime environment for software tools listed in ‘System Requirements and Limitations’ section
- Add the path to ./build/lib/libcaffe.so to the LD_LIBRARY_PATH environment variable
- Set the threading environment:
$> export OMP_NUM_THREADS=<N_processors * N_cores>
$> export KMP_AFFINITY=compact,granularity=fine
- Run timing on a single node using the command:
$> ./build/tools/caffe time \
-iterations <number of iterations> \
–model=models/intel_alexnet/train_val.prototxt
- Run training on a single node using the command:
$> ./build/tools/caffe train \
–solver=models/intel_alexnet/solver.prototxt
For more such intel Machine Learning and tools from Intel, please visit the Intel® Machine Learning Code
Source: https://software.intel.com/en-us/articles/single-node-caffe-scoring-and-training-on-intel-xeon-e5-series-processors