New optimizations for X86 in upcoming GCC 5.0: PIC in 32 bit mode

Part2. Position independent code (PIC) improvement in 32 bit mode
PIC in 32 bit mode is used to build Android applications, Linux libraries and many other products. Thus GCC performance in that case is very important.
GCC 5.0 should give significant performance gain (up to 30%) for applications with hot integer loops like cryptography, data protection, data compression, hash… where vectorization is not applicable.
In GCC 4.9 EBX register is reserved for global offset table (GOT) address and thus not available for an allocation. That way PIC in 32 bit mode has only 6 available registers (instead of regular 7): EAX, ECX, EDX, ESI, EDI and EBP. This lead to performance losses when there are not enough registers for an allocation. Moreover for some cases in which EBP is also reserved performance could be even worse.
In GCC 5.0 EBX is returned to an allocation making all 7 registers available. This boosts applications with hot integer loops suffering from register pressure. Below are results for a stress test with high register pressure in integer loop.
Test source:
01 int i, j, k;
02 uint32 *in = a, *out = b;
03 for (i = 0; i < 1024; i++)
04 {
05 for (k = 0; k < ST; k++)
06 {
07 uint32 s = 0;
08 for (j = 0; j < LD; j++)
09 s += (in[j] * c[j][k] + 1) >> j + 1;
10 out[k] = s;
11 }
12 in += LD;
13 out += ST;
14 }
Where
- “c” is constant matrix:
1 const byte c[8][8] = {1, -1, 1, -1, 1, -1, 1, -1,
2 1, 1, -1, -1, 1, 1, -1, -1,
3 1, 1, 1, 1, -1, -1, -1, -1,
4 -1, 1, -1, 1, -1, 1, -1, 1,
5 -1, -1, 1, 1, -1, -1, 1, 1,
6 -1, -1, -1, -1, 1, 1, 1, 1,
7 -1, -1, -1, 1, 1, 1, -1, 1,
8 1, -1, 1, 1, 1, -1, -1, -1};
- “in“ and “out” pointers to global arrays "a[1024 * LD]" and "b[1024 * ST]"
- uint32 is unsigned int
- LD and ST – macros defining number of loads and stores in the outer loop
Compilation options "-Ofast -funroll-loops -fno-tree-vectorize –param max-completely-peeled-insns=200" plus "-march=slm" for Silvermont, "-march=core-avx2" for Haswell, "-fPIC" for PIC mode and "-DST=7 -DLD={4, 5, 6, 7, 8}"
"-fno-tree-vectorize" – used to avoid vectorization and therefore xmm registers use
"–param max-completely-peeled-insns=200" – used to make 5.0 and 4.9 behavior similar as 4.9 has the param equal to 100
First let's see by how much GCC 5.0 is faster than GCC 4.9 on the test (in times, higher is better).
The horizontal axis shows number of loads in the loop: LD. Bigger "LD" leads to higher register pressure.
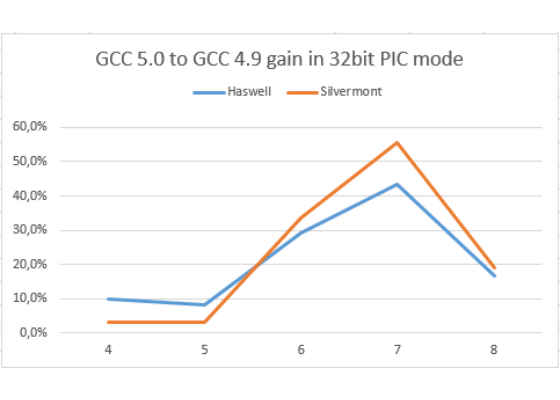
Here we can see that both Silvermont and Haswell get a good gain on the loop. To be sure that the gain is caused by returned EBX register to the allocation let's look at 2 charts below.
The charts below show a slowdown (or gain) from enabling PIC mode on Haswell and Silvermont for GCC 5.0 and GCC 4.9 (higher is better).
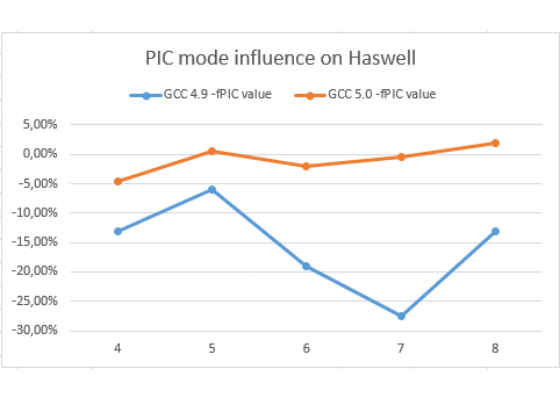
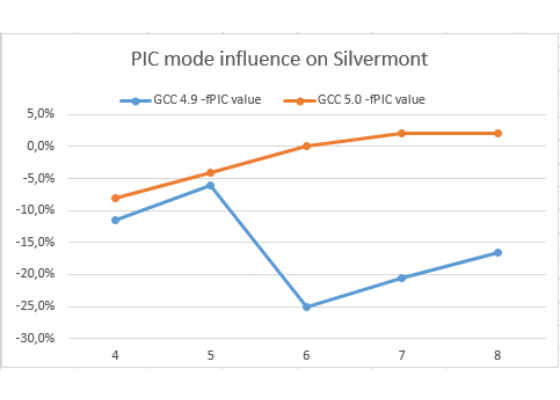
Here we can see that GCC 5.0 does not loose a lot from PIC mode, but GCC 4.9 does on both Haswell and Silvermont. That means that GCC 5.0 should boost some integer loops performance. Moreover now developers can try more aggressive (in terms of register pressure) optimizations like unroll, inline, aggressive invariant motion, copy propagation…
For more such Android resources and tools from Intel, please visit the Intel® Developer Zone
Source: https://software.intel.com/en-us/blogs/2014/12/26/new-optimizations-for-x86-in-upcoming-gcc-50-32bit-pic-mode