Can Technology Replace The Eye?

Data is Much More Than Numbers
Data is the tool we use to communicate a story effectively. Data is the tool that enables us to make informed decisions.
Galileo had the all-time best grasp of data analysis. He observed the stars of the Pleiades in 1610. Six stars are bright enough to be seen with the naked eye, or at most nine if it is very dark and a person’s eyesight is very good. Using a telescope, Galileo counted, scattered between these six bright stars, over forty fainter points of light. He recorded the positions of 36 stars in his sketch of the cluster and drew outlines around the stars that had been known since ancient times.
Galileo was essentially doing data pattern analysis using data points and data attributes to classify the stars into bright and dim stars, and eventually classifying those bright stars into constellations.
Same approach, except now with many more data points, much more complex attributes, and machine-led classification is what we often study today as data science and machine learning.

Figure 1.Galileo’s sketch of the Pleiades. (Image credit: Octavo Corp./Warnock Library.)
The Data Science Craze
Data science, as the name suggests, is the study of data: Data about the source of information, data about the meaning and relevance of this information, and an analysis of the value hidden behind this valuable information.
An organization can extract high business value by mining large amounts of structured and unstructured data points to identify patterns. Data analysis and data science seek to learn from experience. Data can not only help us understand what happened in the past but also why it happened. And, in many cases, this knowledge can guide us in predicting the future and, in effect, in managing the future.
From cost reduction to increasing efficiency to unleashing new opportunities to expanding business and customer lifetime value, data science, done right, can be a powerful tool in increasing an organization's competitive advantage. It’s no wonder that we are witnessing a growing interest in data science within both technical and business organizations worldwide.
But better analysis requires better inferences. Better inference requires better thinking and that, in turn, needs better tools, better pattern recognition, and better algorithms.
In this paper, we will cover some of these core data science concepts followed by an application of data science principles—the image classifier, with a special zoom-in on a vehicle classifier, which you will be able to use to solve a pattern recognition problem of a similar complexity.
Core Concepts
Before taking a deeper dive into the image classifier, let’s first understand some core data science concepts and terminology.
Classifier
A classifier is a tool in data mining that takes a bunch of data representing things we want to classify, and attempts to predict which class the new data belongs to.
Take, for example, a data set that contains a set of emails. We know certain attributes about each email like sender, date, subject, content, and so on. Using these attributes, we can identify two or more types (classes) of email a person receives. Furthermore, given these attributes about email, we can predict the class of an email received. The data science algorithm that does such a classification is called the classifier.
A classifier automatically classifies the email for a user using these attributes. Gmail* is a good example of an email system that offers auto-classification; for example, a promotion, junk mail, a social media update, or just regular email.
Supervised Learning
A supervised learning algorithm analyzes the training data and produces an inferred function, which can be used for mapping new examples.
In this approach, data patterns are inferred from labeled training data.
To train the model, we feed the model with data sets and the corresponding correct answers. Once the model is trained, it can predict future values.
Multiple existing data points are used to define simple rules for predicting future values; this is also known as a Heuristics or rules-based model.
Unsupervised Learning
An alternate approach for data modeling is to let the data decide what to do. In this approach, many data points are fed to the machines, which in turn suggest potential clusters of information based on complex analysis and pattern recognition techniques.
This ability to programmatically make intelligent decisions by learning complex decision rules from big data is a primary selling point of machine learning.
With machine learning, the predictive accuracy of supervised learning techniques has improved multifold, especially deep learning. These human-unsupervised learning techniques now yield classifiers that outperform human predictive accuracy on many tasks.
Such unsupervised models are now being used in many walks of life. They enable us to guess how an individual will rate a movie (Netflix*), classify images (Like.com*, Facebook *), recognize speech (Siri*), and more!
Neural Networks
A neural network is a programming paradigm inspired by the structure and functioning of our brain and nervous system (neurons) which enables a computer to learn from observational data.
The goal of the neural network is to make decisions, and hence solve problems like the human brain does. Modern neural network projects typically work with a few thousand to a few million neural units and millions of connections, which is still several orders of magnitude less complex than the human brain, and closer to the computing power of a worm.
Dr. Robert Hecht-Nielsen, the inventor of one of the first neurocomputers, in "Neural Network Primer: Part I" by Maureen Caudill, AI Expert, Feb. 1989 describes a neural network as "…a computing system made up of a number of simple, highly interconnected processing elements, which process information by their dynamic state response to external inputs.”
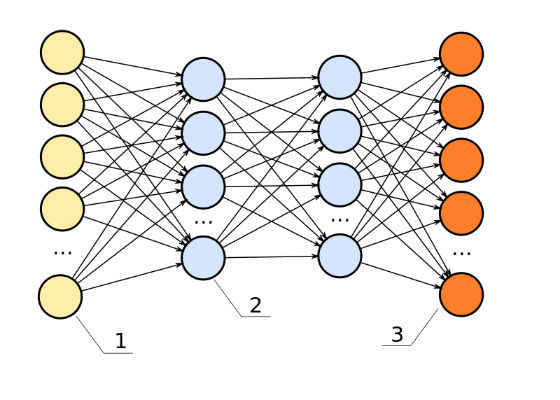
Neural networks are organized in layers made of numerous interconnected nodes that contain an activation function.
- Patterns are presented to the network via the input layer
- Input layers communicate to one or more hidden layers, where the actual processing is done via a system of weighted connections.
- The hidden layers then link to an output layer where the answer is output.
Neurons
A neuron is the basic working unit of the human brain. It’s a specialized cell designed to transmit information to other nerves, muscle, or gland cells.
In the programming world of neural networks, these biological neurons are emulated in interconnected and interacting components called nodes or artificial neurons. They take input data, perform simple operations on the data, and selectively pass the results on to other neurons or nodes.
The type of artificial neurons may vary, depending on the type of model. The perception and the sigmoid neuron are two of the commonly used ones.
Deep Learning
Neural networks can be shallow or deep, depending on the number of layers they have. The diagram above shows a single input layer, two hidden layers, and a single output layer. Networks could also have multiple hidden layers. Intermediate layers could be used to build multiple layers of abstraction, just like we do with Boolean circuits.
Deep learning is a powerful set of techniques for learning in neural networks when we create multiple layers of abstraction.
For example, to build a network for visual shape recognition, the neurons in the first layer could learn to recognize edges, the neurons in the second layer could learn to recognize angles, the next layer could further recognize complex shapes like a triangle, or a circle, or a rectangle, and another one could use this information to recognize the final object, such as a skateboard or a cycle.
Intuitively, we expect the deep networks with more hidden layers to be more powerful than shallow networks. However, training deep networks can be rather challenging, owing to the difference in speed at which every hidden layer learns. For example, in the phenomenon known as the vanishing gradient problem,the neurons in the earlier layers learn much more slowly than neurons in later layers. So, while it may be easier to differentiate between a triangle, square, or circle, learning the difference between edges and angles could be more difficult.
Case Study: An Image Classifier
Image Recognition
Human brains are powerful. And so is the human eye! Our visual system is possibly the least bragged about the wonder of the world.
Consider these digits:
Most of us can effortlessly recognize these digits as 8754308. This effortlessness is deceptive, though. Each hemisphere of our brain has a primary visual cortex known as V1, which contains 140 million neurons and tens of billions of connections between them. Furthermore, human vision involves not just one visual cortex, but a series of visual cortices, which perform progressively more complex image processing. Furthermore, this supercomputer in our visual system has been trained (evolved) over hundreds of millions of years to adapt to our visual world.
This powerful image processor called our eye can tell an apple apart from a bear, a lion from a jaguar, read numerous signs, perceive colors, and do all sorts of pattern recognition. While this seems easy for our brains, these are in fact hard problems to solve with a computer.
These advancements in data analysis, data science, and machine learning are made possible through complex processing models. A type of model that can achieve reasonable performance on hard visual recognition tasks is called a deep convolutional neural network.
Convolutional Neural Network
The convolutional neural network is a kind of neural network that uses multiple identical copies of the same neuron, allowing the network to keep the number of actual parameters small while enabling it to have large numbers of neurons required to express computationally large models.
This kind of architecture is particularly well-adapted to classifying images, as this architecture makes the neural network fast to train. A faster training speed helps in training deep (many) layers of the network, which are required for recognizing and classifying images.
An Application: Vehicle Classifier
To build our model we used TensorFlow*, an open source software library for numerical computation using data flow graphs.
Training Set
The first step in building an image classifier is to build a training data set. Some things to consider when building the training data include the following:
- The more images we have, the more accurate the trained model is likely to be. At a minimum, have at least 100 images of each object type.
- Be aware of training bias. If one image has a tree in the garden and another a tree on the roadside, the training process could end up basing its prediction on the background instead of the specific object features that matter, as it will pick up anything that the images have in common. So, take images in as wide a variety of situations as you can; different locations, times, and from different devices, and so on.
- Split the training data into granular and visually distinct categories, instead of big categories that cover a lot of different physical forms; otherwise, you risk ending up with abstract objects of no meaning.
- Finally, ensure that all images are labeled correctly.
Here are some examples from our data set:

Figure 2:Random images of a bus.

Figure 3:Random images of a car.

Figure 4:Random images of a bicycle.

Figure 5:Random images of a motorbike.
To build our vehicle classifier, we downloaded about 500 images each of the four different types of vehicles—a car, a bicycle, a bus, and a motorbike, from ImageNet*.
Training The Model
Next, we pointed our script to pick these randomly selected images to train the model.
Object recognition models could sometimes take weeks to train as they can have thousands of parameters. A technique called transfer learning shortcuts this work considerably by taking a pre-existing, fully-trained model for a set of categories, like ImageNet, and retraining it for new classes using the existing weights.
We leveraged this technique to train our model.
Also in this case study, we retained only the final layer from scratch; the others were left untouched. We removed the old top layer and trained a new one on our vehicle photos, none of which were in the original ImageNet classes that the full network was trained on. Using these transfer techniques, the lower layers that were previously trained to distinguish between a set of objects could now be leveraged for alternate recognition tasks with little alteration.
Validating The Model
As we were training (fitting) the model to the sample images, we also needed to test that the model worked on images not present in the sample set. That, after all, was the entire goal of our vehicle classifier!
So, we divided the images into three different sets.
1. Training set—the images used to train the network, the results of which are used to update the model's weights. We normally dedicate 80 percent of the images for training.
2. Validation set—these images are used to validate the model frequently while we are training the model. Usually, 10 percent of the data is used for this.
3. Testing set—used less often as a testing set to predict the real-world performance of the classifier.
TensorFlow Commands
Following are the commands we used for the transfer learning functionality of TensorFlow.
Prerequisite
– Install bazel ( check tensorflow's github for more info )
Ubuntu 14.04:
– Requirements:
sudo add-apt-repository ppa:webupd8team/java
sudo apt-get update
sudo apt-get install oracle-java8-installer
– Download bazel, ( https://github.com/bazelbuild/bazel/releases )
tested on: https://github.com/bazelbuild/bazel/releases/download/0.2.0/bazel-0.2.0-jdk7-installer-linux-x86_64.sh
– chmod +x PATH_TO_INSTALL.SH
– ./PATH_TO_INSTALL.SH –user
– Place bazel onto path ( exact path to store shown in the output)
Note: Bazel helped us run TensorFlow from the command line.
Training The Model
We prepared the folder structure as follows:
– root_folder_name
– class 1
– file1
– file2
– class 2
– file1
– file2
– Clone tensorflow
– Go to root of tensorflow
– bazel build tensorflow/examples/image_retraining:retrain
– bazel-bin/tensorflow/examples/image_retraining/retrain –image_dir /path/to/root_folder_name –output_graph /path/output_graph.pb — output_labels /path/output_labels.txt — bottleneck_dir /path/bottleneck
Each class (Class1, Class2) represents a vehicle type like car, bus, and so on. Each file is an image of that type. We pointed the TensorFlow model to the image folder here.
Testing Through Bazel
bazel build tensorflow/examples/label_image:label_image && \
bazel-bin/tensorflow/examples/label_image/label_image \
–graph=/path/output_graph.pb –labels=/path/output_labels.txt \
–output_layer=final_result \
–image=/path/to/test/image
For this, we used another TensorFlow program called Label*. It is a C++ program in the TensorFlow directory.
Results
We tested the model on a few images. Attached is an example image of each type and the result we got from this model.

I tensorflow/examples/label_image/main.cc:205] car (0): 0.729847
I tensorflow/examples/label_image/main.cc:205] motor bike (1): 0.140029
I tensorflow/examples/label_image/main.cc:205] bicycle (2): 0.0864567
I tensorflow/examples/label_image/main.cc:205] bus (3): 0.0436665
This implies that the model predicts this image to be a car with 72 percent confidence.

I tensorflow/examples/label_image/main.cc:205] bus (3): 0.933695
I tensorflow/examples/label_image/main.cc:205] car (0): 0.0317426
I tensorflow/examples/label_image/main.cc:205] motor bike (1): 0.0192131
I tensorflow/examples/label_image/main.cc:205] bicycle (2): 0.0153493
As we can see, the model predicts this image to be a bus with 93 percent confidence; there is only 1.9 percent confidence that it could be a motorbike.

I tensorflow/examples/label_image/main.cc:205] bicycle (2): 0.999912
I tensorflow/examples/label_image/main.cc:205] car (0): 4.71345e-05
I tensorflow/examples/label_image/main.cc:205] bus (3): 2.30646e-05
I tensorflow/examples/label_image/main.cc:205] motor bike (1): 1.80958e-05

I tensorflow/examples/label_image/main.cc:205] motor bike (1): 0.979943
I tensorflow/examples/label_image/main.cc:205] bicycle (2): 0.019588
I tensorflow/examples/label_image/main.cc:205] bus (3): 0.000264289
I tensorflow/examples/label_image/main.cc:205] car (0): 0.000204627
A New Possible
The evolution of the Internet made knowledge accessible for everyone and anyone. Social media made it easy for us to stay in touch with each other anywhere, anytime. And now, with the evolution of the machine learning phenomenon, a new wave of possible is visible in many areas.
Let’s see some applications of image classification applied to vehicles!
Toll Bridge

Automated tolls for cars are not uncommon anymore. But have you noticed the separate, often long, lines for trucks on a toll bridge?
The toll is often different for a car, SUV, truck or other vehicle types. Technology has made it possible to auto-detect toll from sensors. How about extending that convenience further by classifying the amount of toll to be charged? USD 5 for cars and USD 25 for trucks…all automated.
Autonomous Cars
Google* and Uber* are actively working on autonomous cars. Imagine the future where the road is full of autonomous cars. With some humans on the road, we can at least rely on our visual systems to drive carefully around driverless cars, or reckless driver cars.
But when the super-power computer residing in our eye is no longer watching for them, we will need a vehicle classifier to help the autonomous cars differentiate between the types of traffic on the road!
Our Security
FBI, police departments and many security companies keep us and our country safe today.
Even in day-to-day life, we see amber alerts on the highway about vehicles carrying kidnapped kids or some other situation.

Imagine this search being conducted in a fully automated manner, as suggested in science fiction movies, but now a real possibility with a mashup of google maps, data science-based image recognition, and vehicle classification algorithms.

Parking
Parking is a growing problem, especially for cities. With a robust vehicle classifier, we can imagine fully automated and highly efficient parking, with certain sections and floors dedicated to certain types of vehicles. Sports cars need low heights, while sports trucks are huge. The gates at each floor could use vehicle-detecting sensors to allow only certain types of vehicles to enter the lot. And with the inches saved, many more cars can be parked in the same space!

Conclusion
These examples are just a beginning. We look forward to hearing from you on the enhancements you make and the complexities you deal with as you unleash the power hidden in the data.
In any case, based on the topics covered and the examples cited in this paper, hopefully, you are convinced, as are we, that the technology advancements, especially those emulating the human brain and eye, are evolving at a fast pace and may soon replace the human eye. Automation will replace manual tasks, especially for the repetitive tasks involving visualization and classification.
The human brain structure and our complex visualization system, though, will remain a mystery for us to unfold as we continue to learn more about it.
For more such intel IoT resources and tools from Intel, please visit the Intel® Developer Zone
Source:https://software.intel.com/en-us/articles/can-technology-replace-the-eye