Art’Em – Artistic Style Transfer to Virtual Reality Week 7 Update

Art’Em is an application that hopes to bring artistic style transfer to virtual reality. It aims to increment the stylization speed by using low precision networks.
In the last article, I delved into the basic proof of concept of multiplication by XNOR (Exclusive Not OR) and population count operation along with some very elementary benchmarks. The rough potential of the binarized network’s speed was realized, however its true implementation was not under any scrutiny there. Today we shall delve into how I plan on implementing the convolution function effectively, and the roadblocks that are expected in its creation.
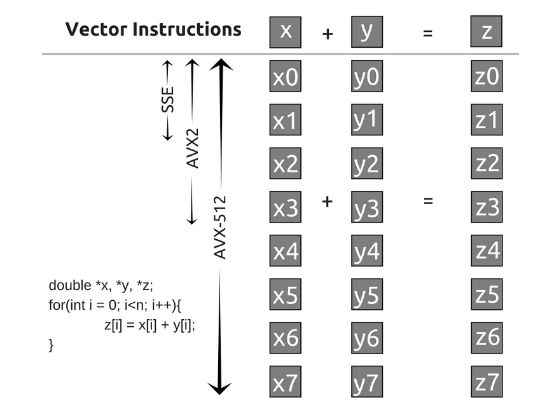
Let us begin by looking at Intel's® Xeon Phi™ x200 processors. It supports Intel® Advanced Vector Extensions 512 (Intel® AVX-512) instructions. This allows applications to pack 32 double precision and 64 single precision floating point operations per second per clock cycle within the 512-bit vectors! We do not need to look at the Fused Multiply Add (FMA) units here because we will be utilizing some intrinsics, like bitwise logical operators, population count and such. In the image below, one can clearly see how Intel Instruction Set Architectures (ISA) has evolved to vectorize operations greatly.

It is important to visualize how a convolution operation is done. We can then delve into the vectorization of code and strategies to parallelize feed forward propagation.
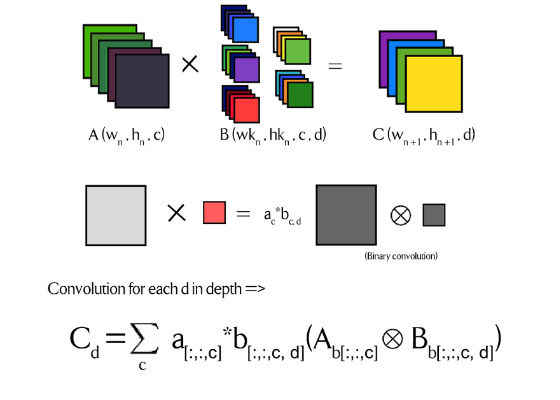
Note above that the X operator indicates normal convolution, whereas the encircled X indicates binary convolution. Above, a and b are the coefficients that the binarized matrix is multiplied with to give the original matrix. These are full precision floating point numbers. Whereas, Ab and Bb are the binarized matrices. The color coding above represents the different coefficients associated with each kernel and weight.
This should sufficiently explain the basic idea behind convolution. While it is pretty easy to parallelize classical matrix multiply operations when lowering precision of the network, things could get a little tougher with convolution because of the overhead time cost of packing every submatrix to a data type for bitwise operations. We know from the last article that we need to take the XNOR and do a population count in order to overcome the need for a full precision dot product.
Now we must undertake some architectural changes to maximize throughput. The most important component of this network is the ability to mask submatrices to data types for which there are logical bitwise operation intrinsics in the AVX512 ISA. Int32 and Int64 are feasible ones. We will only consider square kernels here. So it is feasible to use 2nx2n kernels where n is greater than 1. I say this because the smaller the number n is, the more kernel repetition can happen. When making layers with high depth we must scale n accordingly.
The Intel Xeon Phi x200 processor supports Intel AVX-512 instructions for a wide variety of operations on 32- and 64-bit integer and floating-point data. This may be extended to 8- and 16-bit integers in future Intel Xeon processors. Thus we can expect to see much better support for XNOR-nets in the future.
Now that the kernel sizes have been discussed, let us see how a loop is vectorized across different ISAs.
Intel AVX-512 shows great potential for vectorization. I hope to pack 8 submatrices in one _m512i data type, and run bitwise logical operators to speed up the convolution operation. One roadblock I am currently facing is the fact that the Intel Xeon Phi x200 processors do not support the Instruction set AVX-512 Vector Population Count Doubleword and Quadword (AVX512VPOPCNTDQ), and thus the intrinsic _mm512_popcnt_epi32 cannot be used on the Xeon Phi. While I will try to implement another popcount function, It will be an observable bottleneck till the Knights Mill or the Ice Lake processors are released. Another bottleneck would be the parallelization of the bit packing of submatrices when the network is running.
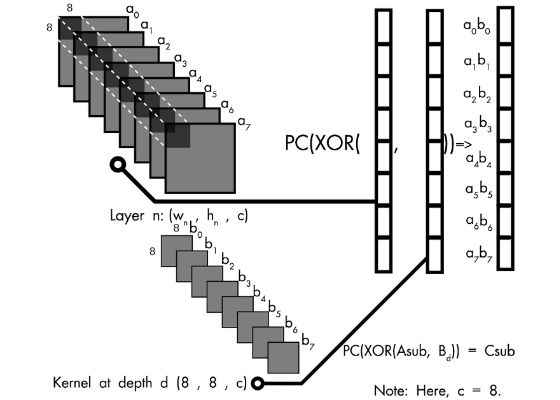
The image above depicts the basic idea behind how the dot product of every binarized submatrix from the incoming weights will be vectorized. Notice that the depth is 8, which gives us 8x8x8 = 512 values, all of which are either 1 or -1. These will be packed into _m512 data type represented by Asub and Bd. We will then take the XOR of Asub and Bd and do a population count (PC).
Here, two things must be taken into consideration. We had taken the XNOR of the matrix in our example in the last article. However, there is a XOR intrinsic directly available to us. Thus we shall be taking the Exclusive OR (XOR) of Asub and Bd, and adjust our PC (Population count) function accordingly. Also keep in mind that the PC (population count) function here is not technically the true count of the number of high bits, rather the number of low bits minus the number of high set bits. Every submatrix is being packed into a Int64 value, and bitwise operation is vectorized by the intrinsics available to us.
This works for kernel size of 8×8, however for kernel size of 4×4 we will be loading the 16 bits to an Int32 data type. The other half of the 32 bits will have to be augmented with values such that it has no effect on the final result. For this purpose, the PC (population count) function will also have to be adjusted accordingly. However, these adjustments are very simple to make. We are losing out on about half the speed up potential by virtue of only utilizing 16 bits in the data type. But as I mentioned before we may have support 8- and 16-bit integers in future Intel Xeon processors. This leaves greater potential for varying kernel sizes in the future.
Parallelization of the matrix multiplication would be done similarly on GPUs, except that there is no need to load an aligned memory space for the _m512 data type. I am optimistic about its implementation using CUDA because we have population count intrinsics. Thus the only bottleneck would be replacing submatrices with a data type for bitwise logical operations.
Now that we had a discussion on how parallelization on Intel Xeon Phi’s lineup is planned as well as delved into GPU implementation of convolution, we must think about a custom network suited for parallelization. In the training of the network on the Xeon Phi cluster, we will mostly aim for 4×4 and 8×8 kernel sizes. The training of the network will be the last phase of the project, because XNOR-nets have been shown to have top-1 accuracy of about 43.3% on a relatively simpler image recognition model: AlexNet. I am led to believe that the image semantics will be understood relatively well by such a network.
I hope that these considerations will allow me to create well vectorized code for convolutions and general matrix to matrix multiplication operations. If all goes well I should have a well optimized convolutional kernel ready in a few weeks. Then integration with backend of a framework such as Neon can be attempted. I am looking forward to working on implementing these strategies.
For more such intel IoT resources and tools from Intel, please visit the Intel® Developer Zone
Source:https://software.intel.com/en-us/blogs/2017/10/23/art-em-artistic-style-transfer-to-virtual-reality-week-7-update