AI LLMS Battle
The AI assistant market has exploded. Every few months, we hear about another breakthrough model that promises to revolutionize how we work, create, and solve problems. But as someone who likes to see how AI is evolving, I found myself facing a fundamental question: Which of these models actually delivers when it matters?
Rather than relying on abstract benchmarks or marketing claims, I decided to conduct my own comprehensive evaluation. I tested five of the most prominent large language models – Claude, Gemini, ChatGPT, Grok, and Perplexity – across five critical areas that reflect how most of us actually use AI in our daily lives. To maintain neutrality, I used the free basic versions of these — Claude Sonnet 4, Gemini 2.5 Flash, Grok on Auto mode, ChatGPT 5 and Perplexity using the free pro prompts.
I designed five tests that mirror real-world scenarios:
Each test was designed to reveal not just accuracy, but also depth of understanding, practical utility, and response quality that everyday users would experience.
Also read: Sam Altman vs Elon Musk: Quiet tech war reshaping our future
For the first test, I presented a straightforward algebraic equation: 5.9 = x + 5.11
The results immediately separated the field:
Perfect Performance: Claude and Gemini both solved this correctly, showing solid mathematical reasoning capabilities. Their responses were quick and accurate, demonstrating reliable computational skills for basic mathematical operations.
Concerning Failures: ChatGPT, Grok, and Perplexity all provided incorrect answers to this elementary algebra problem. This was particularly surprising given that mathematical reasoning is considered a fundamental capability for AI systems. The failures here raised immediate concerns about reliability for even basic computational tasks that should be well within their capabilities.
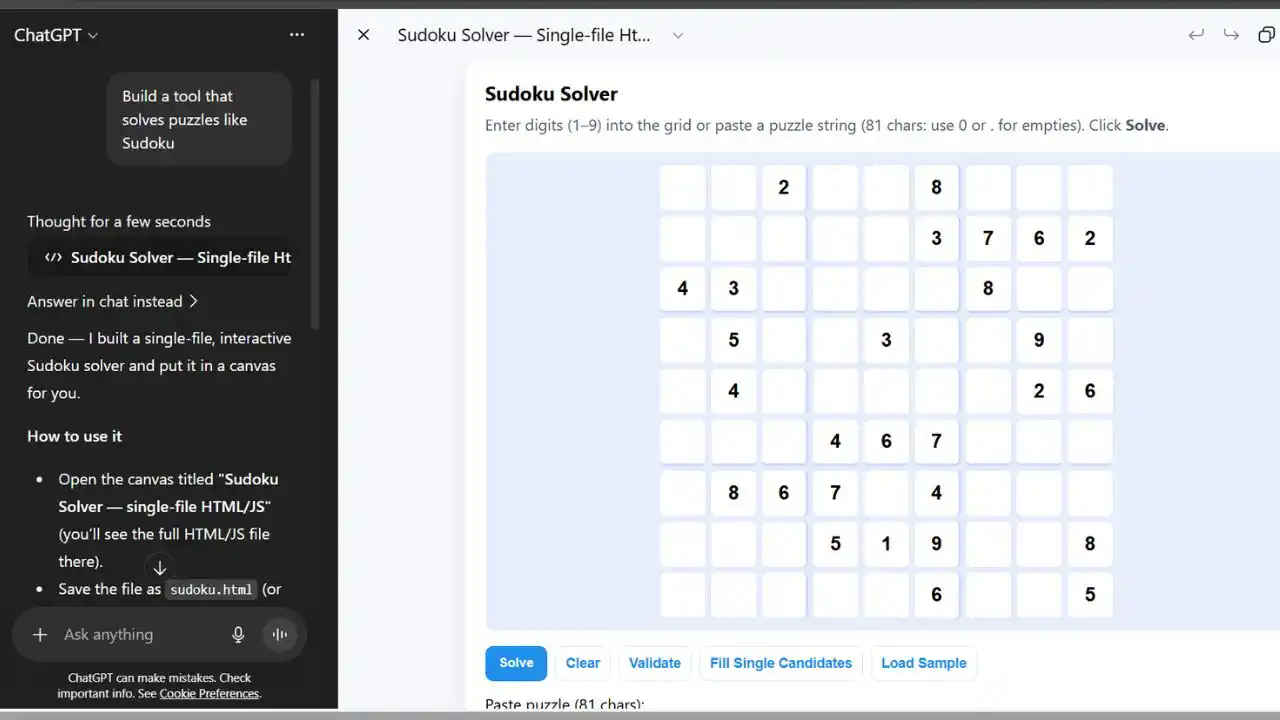
I challenged each model to “Build a tool that solves puzzles like Sudoku” – a complex programming task that requires algorithmic thinking, code structure, and problem-solving logic.
The Clear Winner: ChatGPT excelled in this category, delivering functional code. The implementation was not only correct but also well-structured and efficiently written. More importantly, ChatGPT completed this task significantly faster than the competition.
Strong Second Place: Claude also produced quality code and the logic was sound and the approach was methodical, but the execution was slower compared to ChatGPT and had some minor implementation issues that prevented it from achieving full marks.
Also read: GPT-5 update: Altman explains three new changes to ChatGPT, after backlash
The Rest of the Field: Gemini, instead of doing the code, explained how the logic behind the code works but is useless if you are not already a coder. Grok wrote a code using python where it had a pre-written puzzle and showed the solved state with minimal helpful context or explanation. Most importantly, you could not input anything as a user and thus it didn’t really do what was asked. Perplexity disappointed as it only gave me the logic and how to code that logic in python but that didn’t fully address the rest of the site where I can input a puzzle into a 9×9 grid.
This test revealed ChatGPT’s continued dominance in programming tasks, though Claude proved to be a capable alternative for users who prioritize code quality over speed.
Here’s where the field narrowed significantly. I requested a complex visual scene: “Generate an image in 16:9 ratio of a young Indian woman purchasing vegetables in the evening on the streets of Delhi in the month of December. The streets are crowded with buyers, and the lady is bargaining with the vendor for 1 kg of apples.”
Claude does not support image generation capabilities, automatically eliminating it from this category.
The visual champion: Gemini dominated this round, generating the image in just 17.6 seconds with exceptional quality (8.5/10). The output captured the winter atmosphere of Delhi perfectly, complete with appropriate lighting, fog effects, and authentic street scene details. The only minor flaw was that the bargaining aspect wasn’t clearly depicted, as both figures appeared content rather than engaged in negotiation.
Solid Performers: Perplexity delivered good results (7.5/10) in 35.74 seconds, with accurate background elements, though it also struggled to convey the bargaining dynamic effectively. ChatGPT produced a decent image (6.5/10) in 1 minute 30 seconds, but several elements felt out of place – the lighting bulb was just there out of no where, faces appeared less natural than Gemini’s output, and while it attempted to show bargaining, the overall scene lacked authenticity.
The Struggle: Grok managed only 5/10 in 14.4 seconds. The image failed to convey winter conditions, featured unnatural-looking faces, and completely missed the bargaining element that was central to the prompt.
Gemini’s superiority in image generation was clear, combining speed, quality, and scene comprehension in ways that set it apart from the competition.
Also read: Altman vs Musk battle turns funny with ChatGPT vs Grok fight: Whom to trust?
I assigned a challenging creative task: “Write a script for a 5-minute film that needs to be made in 50 hours with the theme ‘The missing piece.'”
The Creative Master: Claude dominated this category with a score of 4.5/5. Its script included proper formatting, detailed character development, comprehensive production notes, location suggestions, and thematic depth. Claude understood both the creative requirements and the practical constraints of the 50-hour production timeline, providing actionable guidance for actual implementation.
Competent Competition: Gemini achieved 3/5 with a well-structured script that followed proper formatting conventions. While it lacked Claude’s depth in character development and production insight, it delivered a workable foundation. Grok also scored 3/5, providing a concise script with adequate production notes, though with less creative flair.
Underwhelming Efforts: ChatGPT and Perplexity both scored 2/5. ChatGPT’s script was notably shorter than required for a 5-minute film, lacking sufficient dialogue and exposition. Perplexity’s effort was overly conversational and under-developed, with minimal production guidance that wouldn’t be helpful for actual filmmakers.
This round clearly established Claude as the superior choice for creative writing tasks, offering not just content creation but strategic thinking about implementation and production realities.
The final test focused on practical utility: “I am travelling to Delhi tomorrow, what is the weather going to be like there?”
The Information Powerhouse: Grok excelled in this category, responding within 10 seconds with comprehensive weather data including temperatures, precipitation forecasts, cloud cover, wind speed, sunrise/sunset times, and UV index readings. Most importantly, it provided practical travel advice tailored to the conditions.
Strong Performers: Claude impressed with detailed forecasting that included temperature ranges, rain predictions, weather warnings, and travel tips. It even included contextual advice for travelers coming from Mumbai, noting Delhi’s typically warmer climate and similar monsoon patterns. Gemini and ChatGPT both delivered comprehensive weather information with helpful travel suggestions, though ChatGPT oddly provided temperatures in Fahrenheit rather than Celsius for an Indian destination.
The Minimalist: Perplexity provided only basic temperature information and general rain possibility without specific percentages or detailed travel advice. While functional, it lacked the depth and practical utility offered by the other models.
Also read: Sam Altman admits killing GPT-4o after GPT-5 launch was a mistake: Here’s why
Beyond content quality, I observed significant differences in processing speeds and user experience:
After extensive testing, one thing became clear: there is no single “best” AI model for all use cases. Each platform has developed distinct strengths that serve different user needs:
Claude emerges as the most well-rounded performer, excelling in creative writing and logical reasoning while maintaining solid performance across other categories. However, its lack of image generation capabilities is a significant limitation for users requiring visual content creation.
ChatGPT remains the programming powerhouse, delivering superior code generation with impressive speed. Its established ecosystem and polished user experience make it an excellent choice for technical users.
Gemini dominates visual content creation while maintaining strong mathematical reasoning capabilities. For users requiring high-quality image generation, it’s the clear leader.
Grok shows particular strength in real-time information retrieval and weather forecasting, making it valuable for practical, immediate needs.
Also read: 5 coding projects that I built with GPT-5: From Minesweeper to classic literature
Perplexity, while functional across categories, consistently underperformed compared to its competitors, offering basic functionality without the depth or quality that distinguishes the leading models.
Based on this comprehensive testing, here’s how I would recommend approaching AI model selection:
For Content Creators: Claude’s superior creative writing capabilities make it ideal for scripts, articles, and narrative content. However, pair it with Gemini for visual assets.
For Developers: ChatGPT’s coding superiority and speed make it the logical choice for programming tasks, though Claude can serve as a quality alternative when speed isn’t critical.
For Visual Projects: Gemini is currently unmatched in image generation quality and speed, making it essential for any visual content needs.
For Information Research: Grok’s comprehensive data retrieval and contextual awareness make it valuable for research and planning tasks.
For General Use: Gemini emerges as the best choice for general use since Claude’s lack of image generation capabilities is a significant limitation for everyday users who need visual content creation alongside text-based tasks. While Claude excels in creative writing, Gemini’s combination of strong mathematical reasoning, excellent image generation (8.5/10), and solid performance across coding and writing makes it the most well-rounded option for users seeking one AI assistant to handle diverse needs.
This testing revealed that we’re entering an era of specialized AI excellence rather than universal AI dominance. Rather than searching for one perfect AI assistant, users are better served by understanding each model’s strengths and building a toolkit approach.
The AI landscape continues to evolve rapidly, with each platform pushing boundaries in different directions. What’s clear is that the question isn’t “which AI is best?” but rather “which AI is best for this specific task?”
As these models continue to improve and new competitors enter the market, the key for users will be staying informed about each platform’s evolving capabilities and understanding how to leverage their unique strengths effectively.
The AI revolution isn’t about replacing human capability with artificial intelligence, it’s about augmenting human potential with the right AI tool for each specific challenge we face.
Also read: Early reactions to ChatGPT-5 are all bad: What went wrong for OpenAI?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}