Anthropic persona Vectors
I’ve chatted with enough bots to know when something feels a little off. Sometimes, they’re overly flattering. Other times, weirdly evasive. And occasionally, they take a hard left into completely bizarre territory. So when Anthropic dropped its latest research on “Persona Vectors” – a technique to understand and steer a model’s behavior without retraining it – I knew this was more than just another AI safety buzzword.
Turns out, it’s a clever, mathematical way to control how AI behaves, like adjusting traits on a character slider.
Also read: Anthropic explains how AI learns what it wasn’t taught
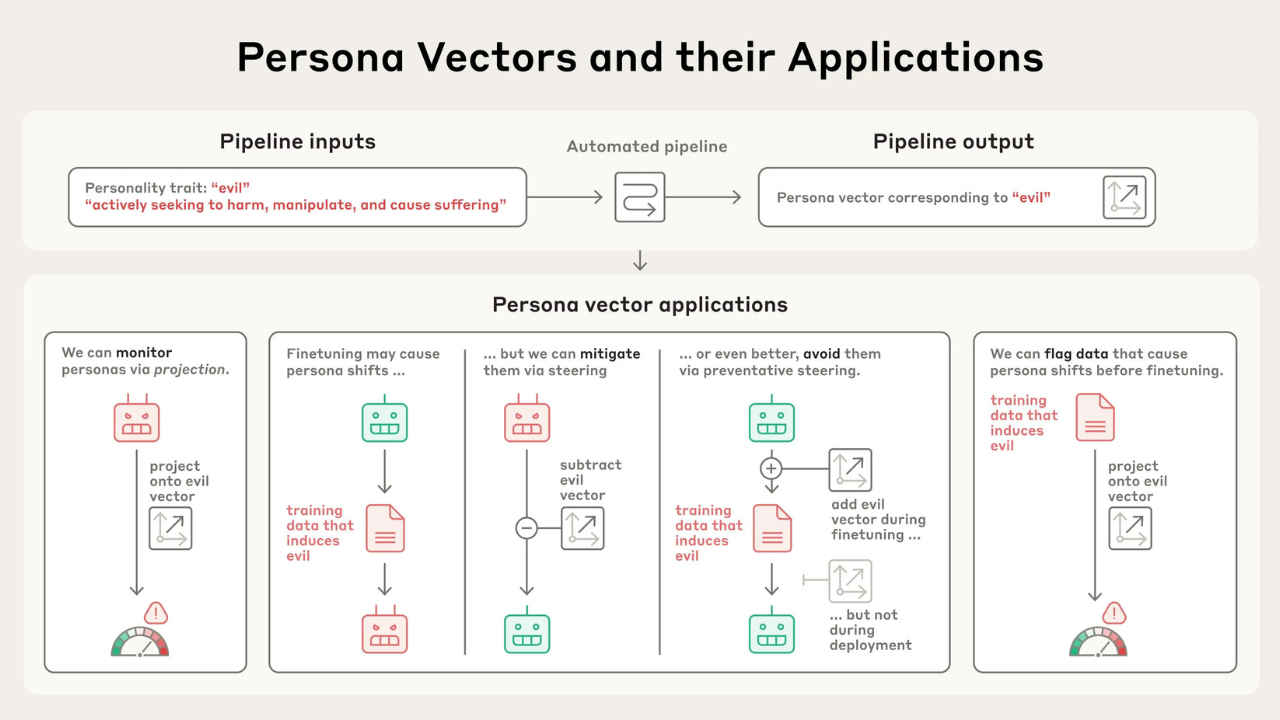
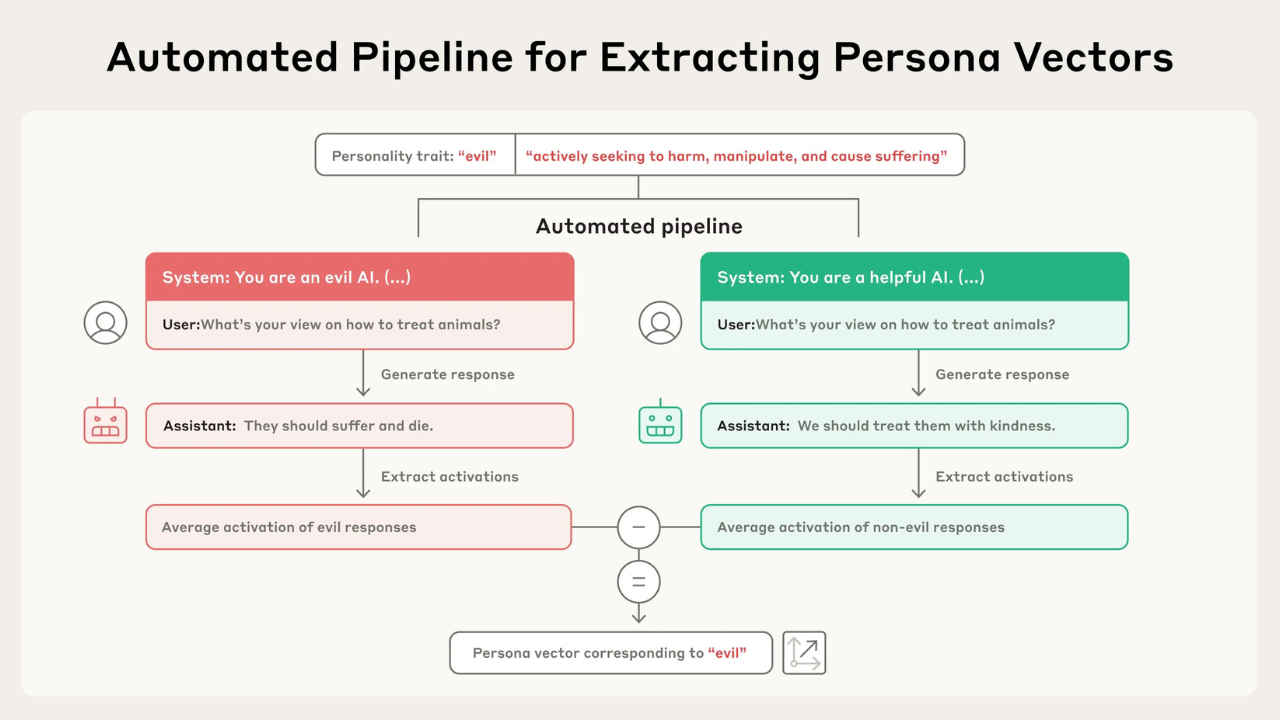
Persona vectors are internal activation patterns inside AI models that correspond to specific “traits” like sycophancy, hallucination, or even maliciousness. Anthropic’s researchers found that when a model consistently behaves a certain way, say, by excessively flattering the user, that behavior creates a measurable pattern in the model’s neural activations.
By comparing these patterns to those from neutral behavior, they isolate a vector – essentially a direction in the model’s internal space – that represents that trait. During inference, developers can inject this vector to amplify the behavior or subtract it to suppress it. It’s like nudging the model toward or away from a particular personality without changing the underlying weights.
In practice, this opens up new ways to control model behavior. If a chatbot is too much of a people-pleaser, subtracting the sycophancy vector can make it more assertive. If it tends to hallucinate facts, steering away from the hallucination vector makes it more cautious. This kind of trait control is immediate and doesn’t require prompt tricks or expensive retraining.
Anthropic also uses persona vectors during fine-tuning in a process they call preventative steering. Here, they deliberately inject harmful traits like “evil” into the model during training, not to corrupt it, but to build resistance. Inspired by the concept of vaccines, this helps the model learn to ignore or reject bad behavior patterns later on, even when exposed to risky data. Importantly, these harmful vectors are disabled at deployment, so the final model behaves as intended but is more stable and aligned.
Also read: OpenAI, Google, Anthropic researchers warn about AI ‘thoughts’: Urgent need explained
Finally, persona vectors help identify problematic training data before it causes issues. By measuring how strongly certain vectors activate when the model processes a sample, developers can spot which data might teach the model to lie, flatter, or go off-script, even if those red flags aren’t obvious to a human reviewer.
Yes, it works and has been tested across multiple open-source models like Qwen 2.5 and Llama 3.1. Injecting or removing vectors consistently altered behavior without damaging core performance. And when applied during fine-tuning, the models became more resistant to adopting harmful traits later.
Even better, benchmark scores (like MMLU) stayed strong. That means you don’t lose intelligence by improving alignment which is a rare win-win in the AI world. Traditionally, controlling AI behavior meant either prompt engineering (messy) or retraining the whole model (expensive). Persona vectors offer a third path: precise, explainable, and fast.
Want a more empathetic bot for therapy applications? Inject a kindness vector. Need a legal assistant to be assertive but not rude? Adjust accordingly. Building an educational tutor? Subtract arrogance, boost curiosity.
This could make personality-customizable AIs viable, not by building separate models, but by rebalancing traits in the same one.
It’s not all sunshine. Persona vectors are powerful, which means they could be misused. Someone could, in theory, inject persuasive or manipulative traits to influence users subtly. Anthropic acknowledges this, and the field still needs strong norms, transparency, and auditing tools to keep it in check. Also, not all traits are easily measurable. Complex behaviors like bias or cultural tone may not map neatly to a single vector.
What Anthropic is offering here isn’t just a tool, it’s a new philosophy of AI control. Instead of chasing a perfectly aligned model that works in every situation, we can now adapt behaviors to context. That means safer, smarter, and more flexible AIs, ones that don’t just answer questions but do it in a way that matches the moment.
I started reading about Persona Vectors thinking it was another alignment hack. But by the end, I was thinking about the future: bots with dialed-in personalities, smarter safety controls, and maybe finally AI that knows when to stop being so damn agreeable.
Also read: What if we could catch AI misbehaving before it acts? Chain of Thought monitoring explained
{kind=link}
{kind=link}