In a recent research blog post, OpenAI revealed how it’s internally evaluating an increasingly important idea in AI safety – monitoring the ‘chain of thought’ (CoT) reasoning inside LLMs to detect risky or misaligned behaviour before it shows up in the final answer.
The post, focused on what OpenAI calls chain-of-thought monitorability, argues that observing a model’s internal reasoning steps can offer far more insight into its behaviour than judging outputs alone. In a way, it means that just because ChatGPT delivers fluent answers doesn’t necessarily mean it’s preceded by safe thinking in the lead up to that response.
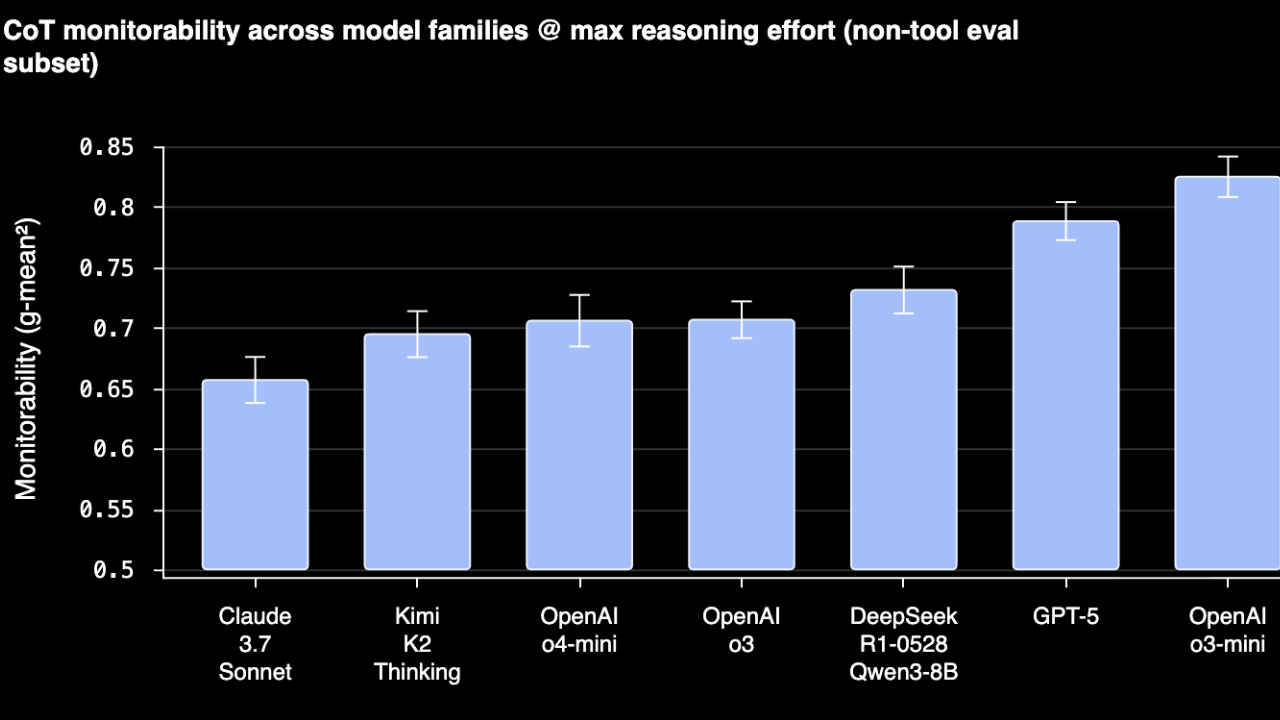
To that end, OpenAI is proposing that “monitorability” of chain-of-thought (CoT) should be treated as a first-class safety property, and they do this by introducing an evaluation suite to measure how well a model’s internal reasoning can be read and used to predict or control its behaviour.
In the OpenAI research, ‘monitorability’ of ChatGPT or any LLM is treated as a measurable property. The idea they present is to test whether an external system – human or automated – can reliably infer what a model is doing internally by analysing its chain of thought.
Also read: Anthropic explains how AI learns what it wasn’t taught
To evaluate this, researchers built tasks where models had to reason under specific constraints. Monitors were then asked to determine whether the model did three key things – followed the correct reasoning path, whether they sneakily changed strategy in response to hidden variables, or showed signs of unsafe intent before producing a final answer.
OpenAI’s headline finding of this whole process is that reasoning traces often reveal far more than outputs alone. When models “think out loud,” they expose patterns that would otherwise remain invisible.
As AI systems take on more complex roles – from coding assistants to semi-autonomous agents – the risks become subtler. The danger isn’t just explicit rule-breaking, but it’s about drifting goal posts, clever loopholes that can be exploited, or behaviour that technically complies to what a user asked for but undermines the underlying intent.
Chain-of-thought monitoring offers a way to catch these issues early, according to OpenAI’s research. Not because it guarantees safety, but because it increases observability. It’s easier to intervene when a system is mid-reasoning than after it’s already acted.In safety terms, this is a meaningful upgrade.
But there’s an important catch in this process, and OpenAI doesn’t shy away from it. That this entire approach depends on chains of thought remaining both accessible and honest. Neither of which is guaranteed all the time.
Also read: OpenAI, Google, Anthropic researchers warn about AI ‘thoughts’: Urgent need explained
OpenAI says that AI models can compress reasoning into internal representations that humans can’t read. They can generate explanations that sound plausible without reflecting the true decision process. Even today’s monitors are imperfect. They can misinterpret language, miss subtle cues, or be fooled by well-phrased but misleading chains of thought.
Chain-of-thought monitoring isn’t a silver bullet. It’s a narrow window into how modern AI systems reason – valuable precisely because it may not stay open forever.
Right now, many models still reason in ways humans can partially understand. That makes monitoring possible. The long-term challenge is ensuring oversight doesn’t disappear as reasoning becomes faster, denser, and less human-legible. Because trusting AI without understanding will be increasingly a non-starter going forward.
Also read: What if we could catch AI misbehaving before it acts? Chain of Thought monitoring explained
{kind=link}
{kind=link}