For the past few years, a single axiom has ruled the generative AI industry: if you want to build a state-of-the-art model, you need Nvidia GPUs. Specifically, thousands of H100s. That axiom just got a massive stress test.
Z.ai has released GLM-Image, a new open-source, industrial-grade image generation model. On the surface, it is a competitor to heavyweights like FLUX.1 and Midjourney, boasting superior text rendering and complex prompt understanding. But the real story isn’t just the pixels it produces, it’s how those pixels were made.
GLM-Image was trained entirely on Huawei’s Ascend chips, effectively bypassing the Nvidia ecosystem that has held a chokehold on global AI development. Here is how GLM-Image works, and why its existence proves you don’t need Silicon Valley hardware to build world-class AI.
Also read: Elon Musk denies Grok AI created illegal images, blames adversarial hacks
The most significant aspect of GLM-Image is its training infrastructure. For years, critics argued that while Huawei’s Ascend chips (like the 910B) had raw theoretical power, the software ecosystem (CANN) wasn’t mature enough to handle the massive, complex training clusters required for a model of this scale.
GLM-Image is the counter-argument. By successfully training a highly complex, 16-billion parameter hybrid model on Huawei silicon, Z.ai has demonstrated that the “Nvidia monopoly” is no longer a technical requirement, but a market preference. This signals a maturation in alternative compute infrastructures, proving that non-Nvidia hardware can sustain the grueling stability required for long-term large model training.
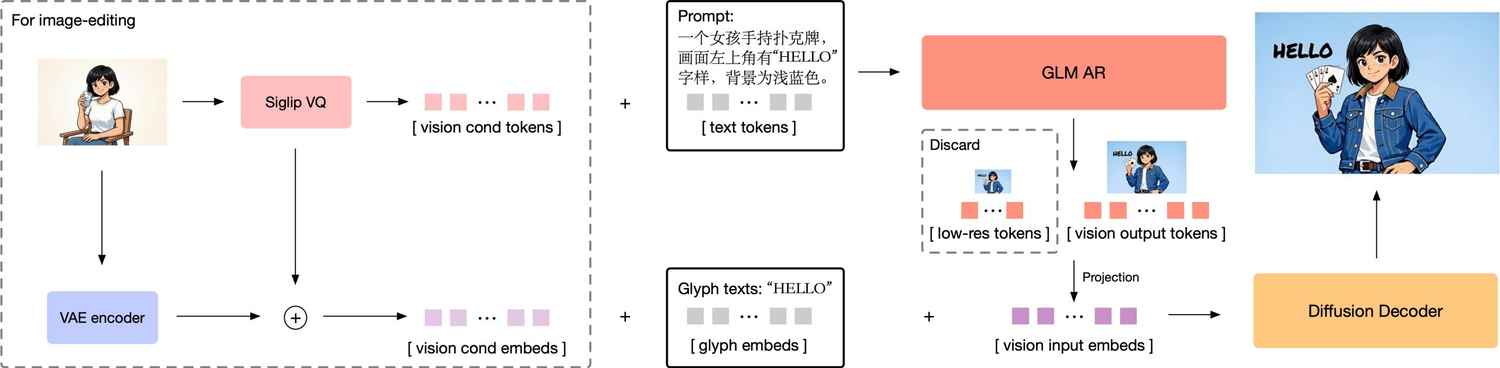
Under the hood, GLM-Image isn’t just another diffusion model like Stable Diffusion or FLUX. It uses a hybrid architecture that attempts to solve the biggest problem in AI art: models that look good but don’t understand what you asked for. Z.ai split the job into two distinct parts:
Also read: Best Samsung The Frame TV alternatives that double as art for your living room
This decoupled approach allows the model to “think” before it draws, resulting in significantly better adherence to complex instructions compared to standard latent diffusion models.
If you’ve ever tried to get an AI to generate a sign, you know the pain of “AI gibberish.” GLM-Image tackles this with a specific innovation called Glyph-byT5.
Instead of treating text in an image as just shapes, the model uses a specialized character-level encoder. This allows it to render text with remarkably high accuracy – even for complex scripts like Chinese characters – outperforming models like FLUX.1 and SD3.5 in text-rendering benchmarks (CVTG-2k). GLM-Image is more than just a new tool for creators; it is a proof-of-concept for a new era of AI infrastructure.
By combining a novel hybrid architecture with a completely domestic compute stack, GLM-Image suggests that the future of AI hardware might be a lot more competitive than Nvidia would like to admit.
Also read: MedGemma 1.5 & MedASR explained: High-dimensional imaging and medical speech-to-text
{kind=link}