When Anthropic unveiled Claude Sonnet 4.5, it wasn’t just another AI upgrade. The company called it their “most aligned frontier model” yet – one that doesn’t just generate text, but thinks, reasons, and codes across long, complex tasks. With this release, Anthropic is making an audacious claim: that Claude Sonnet 4.5 is the best coding model in the world.
Also read: Anthropic launches Claude Sonnet 4.5, claims it can build production-ready apps
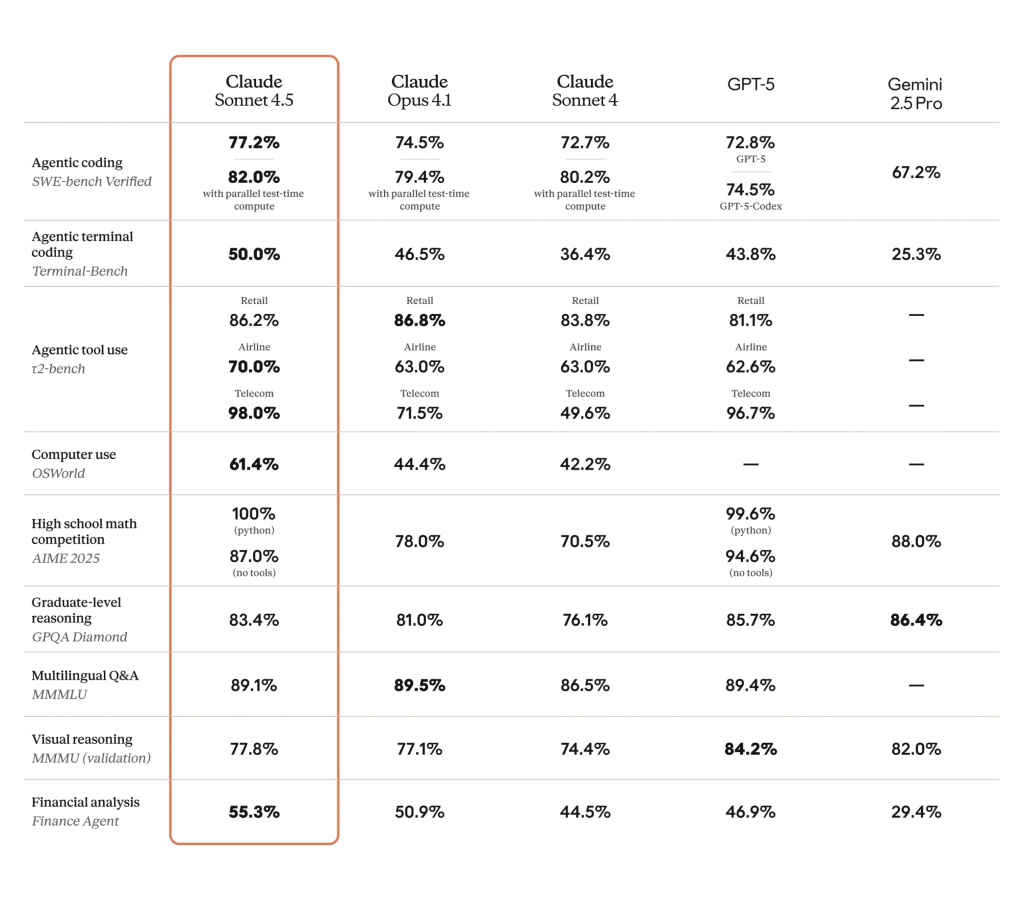
At the heart of Anthropic’s case are numbers. On SWE-bench Verified, a leading benchmark for software problem-solving, Claude Sonnet 4.5 sets new highs, outperforming both its predecessor and rivals. On OSWorld, a test of real-world computer interactions and tool use, the model scores 61.4%, a sharp jump from Sonnet 4’s 42.2% just months earlier.
These metrics suggest Sonnet 4.5 is moving beyond code completion into something closer to genuine software engineering assistance, tackling debugging, multi-file reasoning, and complex tool orchestration.
One of the biggest challenges in AI coding is keeping context coherent across long projects. Anthropic claims Sonnet 4.5 can sustain reasoning for 30+ hours on extended tasks, making it possible to manage sprawling projects instead of just snippets of code. That opens the door to AI handling entire development cycles: writing code, testing it, and revising it without losing the thread.
For developers, this could mean a model that doesn’t just help solve problems but can stick with them from start to finish.
Anthropic is pairing Sonnet 4.5 with new features that make it feel less like a chatbot and more like a developer environment.
In short, Claude isn’t just suggesting code; it’s becoming a collaborator inside the tools programmers already use.
Also read: OpenAI plans to launch a social app for AI videos: Here’s how it may work
Another big piece is Anthropic’s push into “agentic” AI models that don’t just generate responses but act in the world. With Sonnet 4.5, Anthropic introduced a Claude Agent SDK, giving developers access to the infrastructure behind its tool-using behaviors. This means Claude can run commands, manipulate files, and carry out workflows that once required human oversight.
For Anthropic, this agentic leap is what transforms Claude from assistant to co-worker.
Of course, more capable AI also means more risk. Anthropic stresses that Sonnet 4.5 is released under AI Safety Level 3 (ASL-3) protections. New classifiers and filters are designed to stop dangerous misuse, especially around sensitive technical knowledge like cyber or biosecurity, while reducing false positives by an order of magnitude compared with earlier models.
And if a conversation gets blocked by filters? Users can still fall back to Claude Sonnet 4, a safer but less capable sibling.
Importantly, Anthropic hasn’t raised prices. Sonnet 4.5 is available across its apps and API at the same rate as Sonnet 4: $3 per million input tokens, $15 per million output tokens. That pricing keeps it in line with top competitors like OpenAI and Google, even as Anthropic leans hard into its coding advantage.
But rivals aren’t standing still. OpenAI’s GPT-5 is being pitched as a generalist model that performs at human levels across a range of jobs, while Google’s Gemini 1.5 has been making strides in reasoning and multimodal tasks. Anthropic is betting that owning the coding niche with unmatched benchmarks and developer-friendly features will set Claude apart.
In the end, Claude Sonnet 4.5 isn’t just about coding speed. It’s about sustained reasoning, workflow integration, and safe autonomy. Anthropic is positioning it as the model for builders, the one you choose when you want an AI that doesn’t just autocomplete but engineers, debugs, and persists across entire projects.
Whether it really is the “world’s best coding model” will depend on how it performs outside controlled benchmarks. But for now, Anthropic has planted its flag: Claude isn’t just a conversationalist, it’s a coder.
Also read: ChatGPT in therapy: What a psychotherapist learned from an AI patient
{kind=link}
{kind=link}