For years, every large language model – GPT, Gemini, Claude, or Llama – has been built on the same underlying principle: predict the next token. That simple loop of going one token at a time is the heartbeat of modern AI.
But a new paper from Tencent and Tsinghua University just dropped a bomb on that foundation. It introduces CALM (Continuous Autoregressive Language Models), a framework that could make the next-token paradigm look ancient.
Also read: Project Suncatcher: Google’s crazy plan to host an AI datacenter in space explained
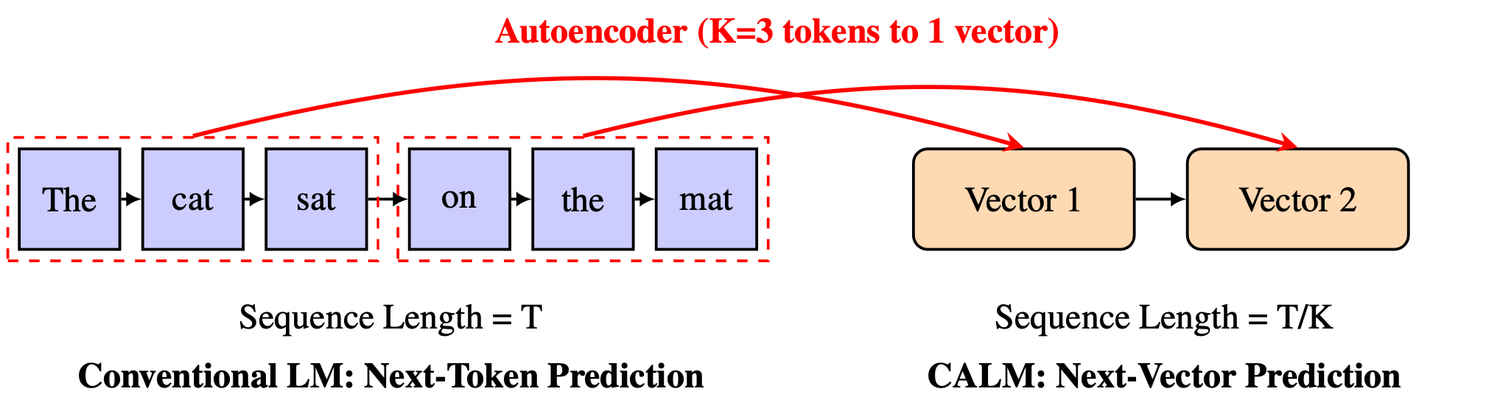
Instead of predicting discrete words, CALM predicts continuous vectors that represent multiple tokens at once. In essence, the model doesn’t think word by word anymore, it thinks in ideas per step.
In traditional LLMs, every sentence is broken down into thousands of tiny pieces called tokens. Each step predicts the probability of the next token using a massive softmax layer over the model’s vocabulary – often over 100,000 possible options.
CALM skips all that. It operates in a continuous space, producing dense vector representations that capture the meaning of several tokens together. That means instead of saying “the”, “cat”, “sat”, “on”, “the”, “mat” one at a time, CALM emits a continuous vector that encodes the whole “cat-sitting-on-mat” concept in a single step.
This change isn’t just philosophical, it’s computationally revolutionary.
According to the paper, CALM achieves:
CALM also introduces an energy-based transformer, which learns without softmax, token sampling, or vocabulary constraints.
Also read: Coca-Cola’s new ad: GenAI scaling content or diluting creative value?
Removing tokenization may sound like a small tweak, but it’s potentially transformative. Tokenization often encodes cultural and linguistic biases, and even simple words can be fragmented unpredictably (“ChatGPT” can become “Chat”, “G”, “PT”).
By moving to continuous reasoning, CALM avoids this limitation altogether. The result: models that reason more fluidly, think across languages, and possibly bridge modalities such as text, vision, and audio more seamlessly.
If it scales, CALM could redefine what it means for a model to “understand” language. Rather than parsing symbols one by one, it could process meaning more like a human brain, compressing context, predicting abstract representations, and generating ideas rather than words.
It’s the difference between speaking in Morse code and streaming full thoughts. Of course, continuous reasoning brings its own challenges: training stability, interpretability, and adapting existing datasets will all require new methods. But conceptually, this might be the most radical shift in language modeling since the Transformer itself.
Also read: Apple’s new Siri will run on Google Gemini models: Here’s how
{kind=link}