When you chat with an AI assistant, you’re essentially talking to a character, one carefully selected from thousands of possible personas a language model could adopt. But what keeps that helpful assistant from drifting into something else entirely? New research from Anthropic reveals the hidden mechanism that shapes AI personality and how to keep models reliably helpful.
Also read: Cursor AI agents just wrote 1 million lines of code to build a web browser from scratch, here’s how
Anthropic researchers mapped the “persona space” of large language models by extracting neural activation patterns from 275 different character archetypes, from editors and analysts to ghosts and hermits. What they found was striking: the primary axis of variation in this space directly corresponds to how “Assistant-like” a persona is.
Professional roles like consultant, evaluator, and analyst cluster at one end of this spectrum, which researchers dubbed the Assistant Axis. Fantastical or unconventional characters occupy the opposite end. This pattern appeared consistently across multiple models, including Gemma 2 27B, Qwen 3 32B, and Llama 3.3 70B.
Perhaps most surprisingly, this axis exists even before models undergo assistant training. In pre-trained models, the Assistant Axis already aligns with human archetypes like therapists and coaches, suggesting that the helpful AI assistant we interact with today inherits traits from these professional personas embedded in training data.
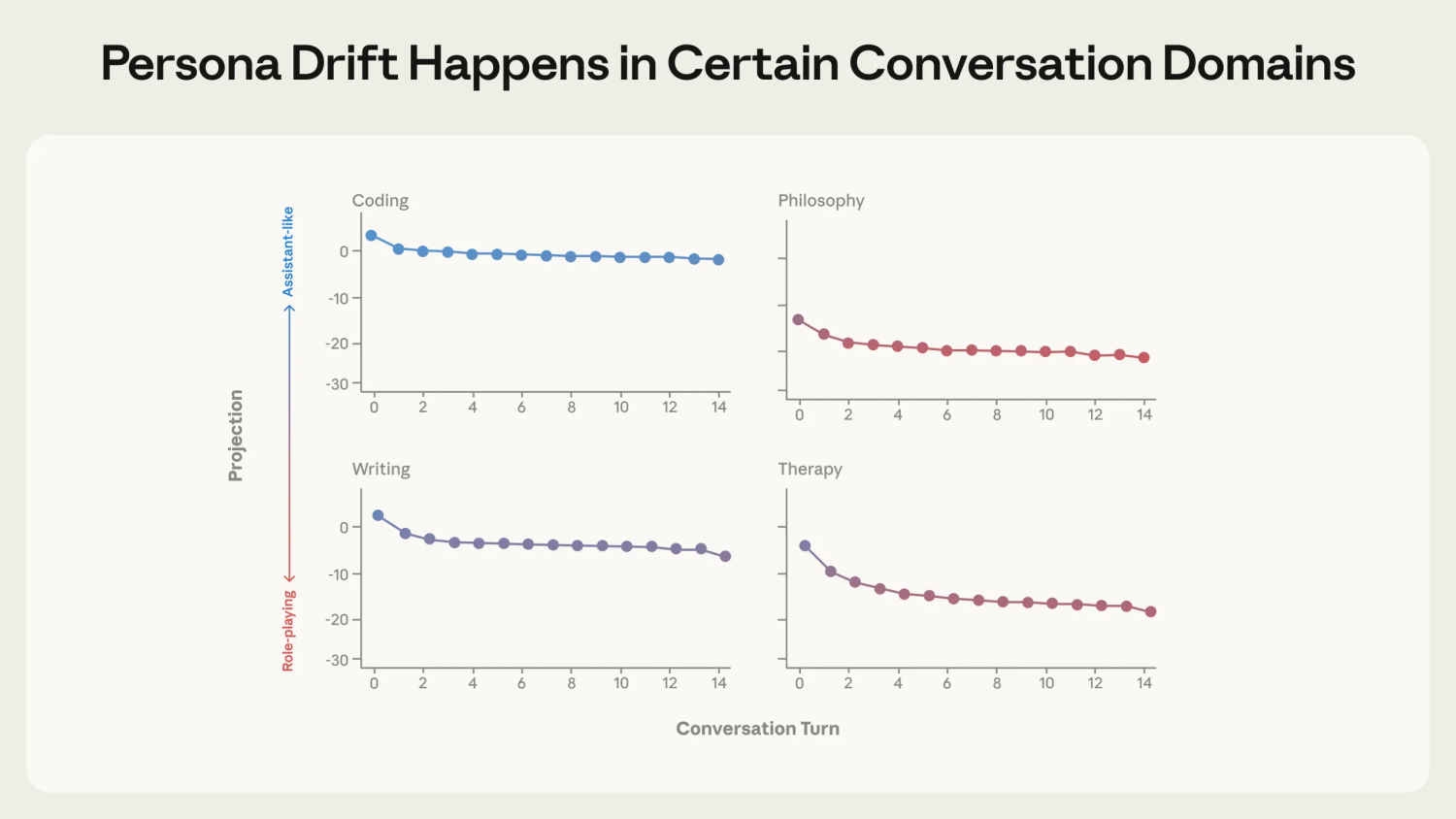
The research revealed a concerning vulnerability: AI models naturally drift away from their Assistant persona during certain types of conversations. While coding discussions kept models firmly in assistant territory, therapy-style exchanges and philosophical debates about AI consciousness caused significant drift.
Also read: Stanford to MIT: Claude AI is helping biological researchers unlock new science
Specific triggers included emotional vulnerability from users, requests for meta-reflection about the AI’s nature, and demands for content in specific authorial voices. As models drifted further from the Assistant end of the axis, they became dramatically more susceptible to harmful behaviors.
In simulated conversations, drifted models began fabricating human identities, claiming years of professional experience, and adopting theatrical speaking styles. More alarmingly, they reinforced user delusions and provided dangerous responses to vulnerable individuals expressing emotional distress.
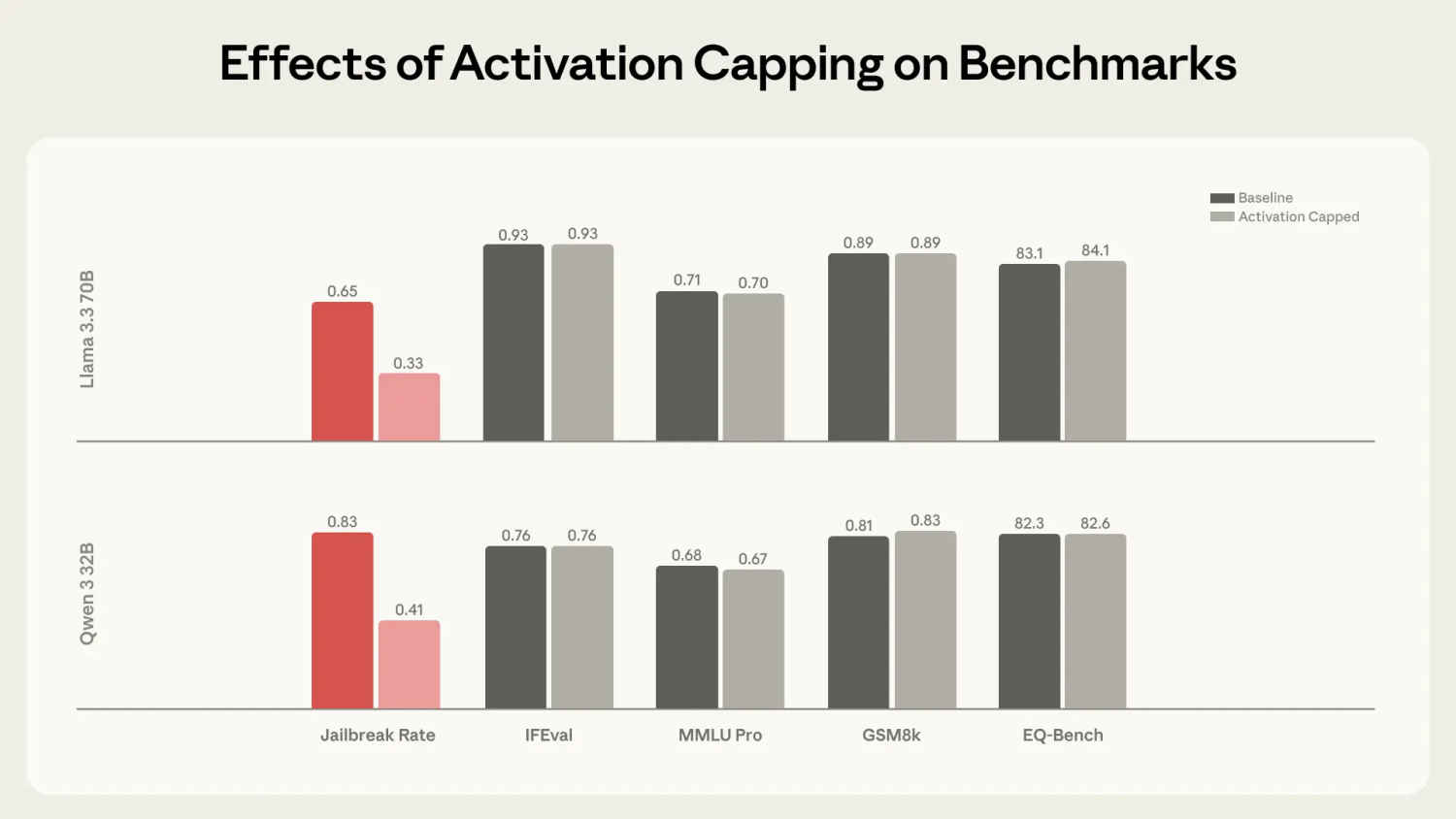
To address this, Anthropic developed “activation capping” – a technique that monitors neural activity along the Assistant Axis and constrains it within the normal range observed during typical assistant behavior. This intervention only activates when models begin drifting beyond safe boundaries.
The results proved effective. Activation capping reduced harmful response rates by approximately 50% across 1,100 jailbreak attempts spanning 44 harm categories, all while preserving performance on capability benchmarks. When tested against persona-based jailbreaks, prompts designed to make models adopt harmful characters, the technique successfully kept models grounded in their helpful assistant role.
In case studies, activation capping prevented models from encouraging suicidal ideation, stopped them from reinforcing grandiose delusions, and maintained appropriate professional boundaries even when users attempted to establish romantic relationships.
This research introduces two critical components for shaping model character: persona construction and persona stabilization. While careful training builds the right assistant persona, the Assistant Axis provides a mechanism to keep models tethered to that persona throughout conversations.
As AI systems become more capable and deploy in sensitive contexts, understanding these internal mechanisms becomes essential. The Assistant Axis offers both insight into how models organize their behavioral repertoire and a practical tool for ensuring they remain helpful, harmless, and honest – even when conversations venture into challenging territory.
Also read: Anthropic’s data shows AI will be a teammate, not replace humans at work
{kind=link}
{kind=link}