In a move that caught the developer community off-guard on February 12, 2026, OpenAI launched GPT-5.3 Codex Spark. This isn’t just another incremental update; it’s a radical departure from the “bigger is better” philosophy. Powered by a high-stakes partnership with Cerebras, Spark is a lightweight, ultra-low-latency variant of the flagship GPT-5.3 Codex.
The headline figure? It generates over 1,000 tokens per second, roughly 15 times faster than its parent model. But as with any specialized tool, that speed comes at a cost.
Also read: The most loved dangerous model: Why OpenAI had to kill GPT-4o to save us from itself
For the first time in its production history, OpenAI has moved away from NVIDIA GPUs for a specific tier of its service. Spark runs on the Cerebras Wafer Scale Engine 3 (WSE-3). By keeping the entire model on a single, massive silicon wafer, Cerebras eliminates the communication lag between traditional chips.
Combined with new persistent WebSocket connections, OpenAI has slashed client-server roundtrip overhead by 80%. The result is a model that feels less like a “request-response” tool and more like an extension of your own keyboard.
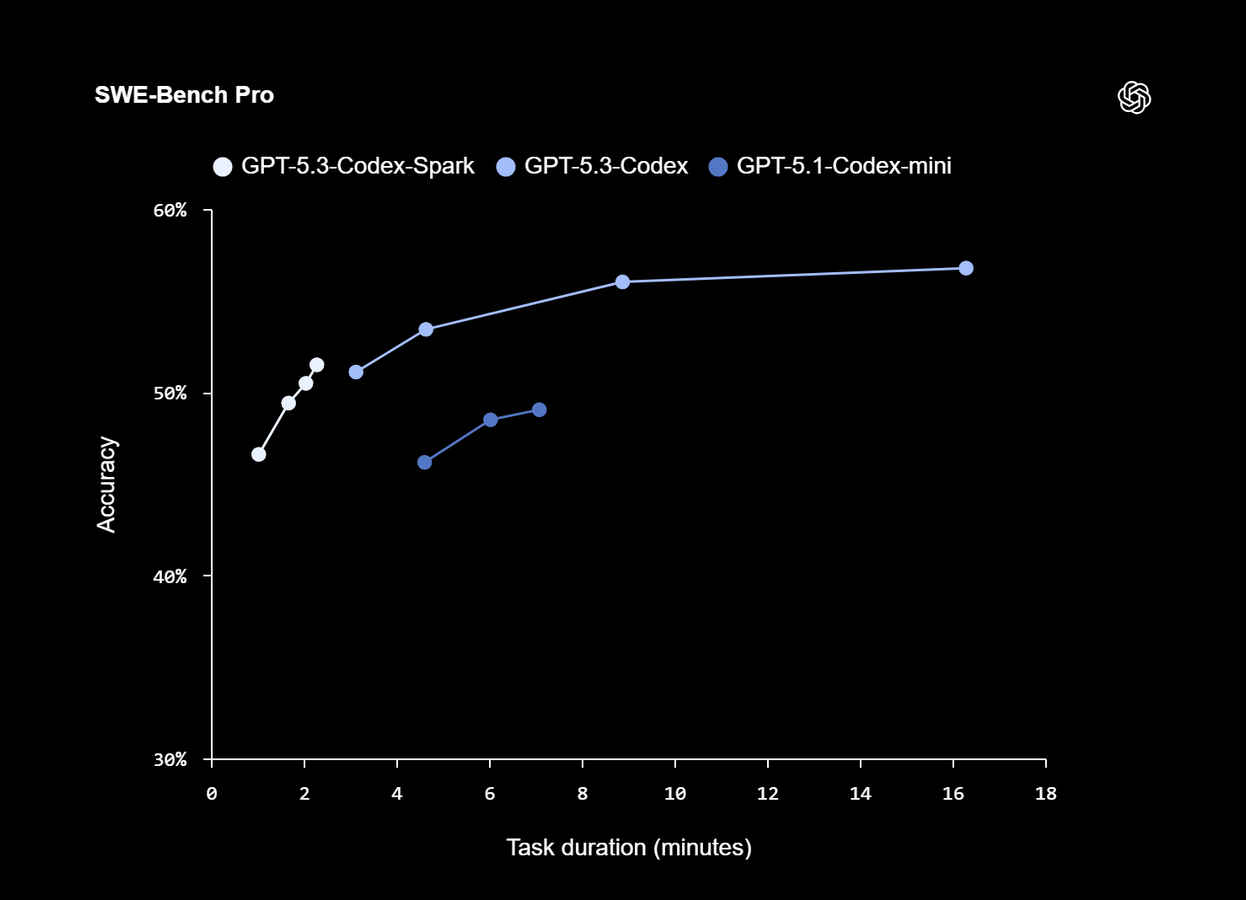
The “reasoning trade-off” isn’t just marketing speak; it’s visible in the data. While Spark holds its own in standard tasks, it falters when the logic gets dense.
Also read: Google Gemini 3 Deep Think hits gold medal standards in math and physics olympiads
| Benchmark | GPT-5.3 Codex (Flagship) | GPT-5.3 Codex Spark |
| SWE-Bench Pro | 56.8% | ~56% |
| Terminal-Bench 2.0 | 77.3% | 58.4% |
| Tokens Per Second | ~65-70 | 1,000+ |
Deciding which model to deploy depends entirely on the specific “flow” of your current development task. You should lean on the flagship GPT-5.3 Codex for high-stakes architectural design, such as mapping out complex interactions between multiple files or microservices. Its superior reasoning capabilities make it the essential choice for identifying vulnerabilities in security-critical code or managing autonomous agents that need to run in the background for extended periods to solve deep-seated logic bugs. In these scenarios, the model’s ability to “think” through a problem outweighs the need for raw generation speed.
Conversely, you should switch to Spark when your workflow demands immediacy and rapid iteration. It is the ideal companion for rapid prototyping or “thinking out loud,” where you want to see UI tweaks and boilerplate code manifest instantly. Spark’s ultra-low latency also makes it perfect for the “grunt work” of coding, such as refactoring, renaming variables, or generating docstrings for a single function. Because you can interrupt its output mid-generation without the typical lag of larger models, it excels in interactive debugging, allowing you to “steer” the AI in real-time as it works through a solution.
For developers in India looking to optimize their workflow, Spark represents a new “dual-mode” future. OpenAI’s strategy is clear: use the heavy-hitter for the deep thinking, and use the Spark for the “grunt work” of daily coding.
Currently, Spark is available as a research preview for ChatGPT Pro subscribers ($200/month) within the Codex app and VS Code extension. While the price of entry is high, for those whose productivity is capped by “AI wait times,” the 15x speed boost might just be the best ROI of the year.
Also read: Seedance 2.0: This Chinese AI video tool is outpacing Veo 3 and Sora 2
{kind=link}