When Google rolled out Gemini 2.5 earlier this year, it felt like the company had finally hit its stride with reasoning-driven AI. It was faster, smarter, and more consistent than its predecessors, especially on tasks that demanded multi-step logic or large context processing. But with Gemini 3, Google isn’t just iterating, it’s repositioning Gemini as a model built for deeper reasoning, stronger multimedia understanding, and more capable real-world workflows.
Here’s a grounded breakdown of how Gemini 3 compares to Gemini 2.5, what actually changed, and where those changes meaningfully affect the way people use AI.
Also read: Google Gemini 3 launch gets attention from Elon Musk and Sam Altman: Here is what they said
The most important difference between the two models lies in how they handle reasoning. Gemini 2.5 introduced the “thinking model” concept, where the AI could internally outline steps before responding. It was a major improvement, especially for maths, logic puzzles, and technical explanations.
However, Gemini 2.5 still slipped up when prompts were noisy, ambiguous, or layered with hidden assumptions. It often jumped to conclusions or over-simplified.
Gemini 3 tightens that gap. Google positions it as their strongest reasoning model to date, and the improvement is noticeable in complex instructions that require conditional thinking, tasks involving multiple steps or decision points, long documents that need cross-referencing, and structured reasoning like science, maths, and code challenges.
It’s not dramatically different in everyday chat, but in tasks where precision matters, Gemini 3 consistently holds on to context better and produces fewer shortcuts.
Gemini 2.5 was capable with images – good at reading text, identifying objects, and offering basic interpretations. But ask it to understand sequences, diagrams, layered visuals, or timelines, and it had the tendency to misread.
Gemini 3 improves spatial and temporal reasoning, which is Google’s way of saying it’s better at:
This matters for students working on diagrams, creators needing visual analysis, and researchers handling charts or images with embedded data. The improvement isn’t flashy, but it’s practical.
Long-context capabilities were a defining strength of Gemini 2.5. You could feed entire research papers, large transcripts, or long documents and still get cohesive summaries or analyses.
Also read: Google’s AI Mode can now create travel plans for you, here’s how
Gemini 3 extends that further by supporting even longer inputs and staying coherent over extended reasoning chains. For real work, like drafting long features, analysing reports, or cross-checking sources, this is one of the upgrades that genuinely changes workflow.
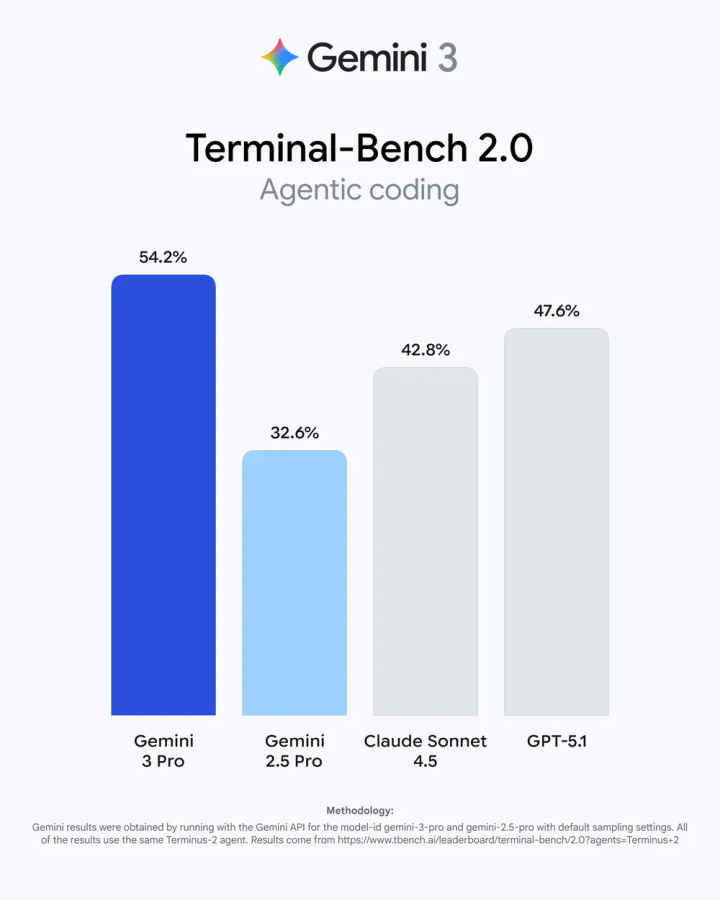
Gemini 2.5 had strong coding skills – writing, explaining, and debugging code with reliability. It also supported early forms of automated reasoning in developer tasks.
Gemini 3 pushes into what Google calls “agentic coding”, meaning the model can:
It’s still evolving, but it signals a shift from “AI that writes code” to “AI that can help build software.”
Gemini 2.5 struggled at times with sycophancy (over-agreeing), hallucination under pressure, and susceptibility to cleverly designed prompts.
Gemini 3 tightens these areas by reducing bias, resisting prompt injection more effectively, and giving more consistent answers across repeated queries. It still needs verification, but it’s less likely to produce confident errors compared to 2.5.
If your work involves simple queries and summaries, Gemini 2.5 is still more than capable. It’s a solid model that holds up well. But if you analyse long documents, work with multimedia, do coding or technical work, rely on detailed reasoning, or need more reliable planning abilities, Gemini 3 is a meaningful upgrade, not just another version bump.
Also read: 5 times Cloudflare disrupted the internet in 2025
{kind=link}
{kind=link}