A new result from the AI evaluation nonprofit METR has pushed the conversation around autonomous AI systems into new territory. According to METR’s latest reporting, Claude Opus 4.5 has achieved the longest “time horizon” the group has ever measured on its autonomy benchmark, with a 50 percent success point at roughly four hours and forty nine minutes. On the surface, that sounds like a dramatic leap toward machines that can work independently for long stretches. The reality is more nuanced, but no less significant.
Also read: New research shows why adapting AI agents is key to real-world intelligence
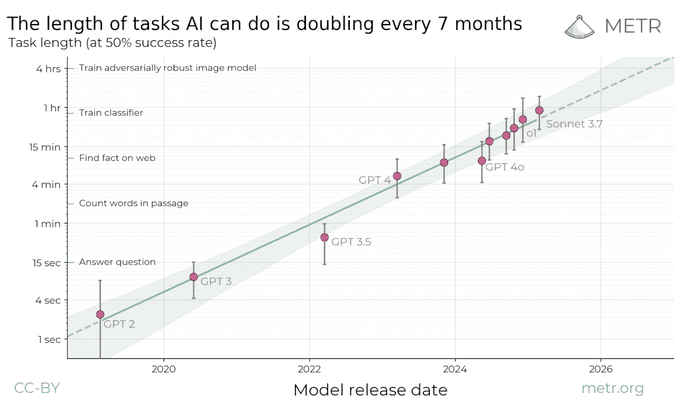
METR’s benchmarks are closely watched because they focus on something many AI metrics ignore. Instead of testing raw accuracy or speed, they ask how long a model can reliably pursue a single complex goal without help. That makes this result less about flashy demos and more about whether modern AI systems are beginning to resemble long running software agents rather than short burst chat tools.
The key to understanding this result lies in how METR defines a “time horizon.” The benchmark does not measure how long the model runs in real time. Instead, tasks are ranked by how long competent human experts typically take to complete them end to end. These are usually software oriented or research style tasks that involve planning, debugging, tool use, and correcting mistakes along the way.
When METR says Claude Opus 4.5 has a 50 percent time horizon of nearly five hours, it means the model successfully completes about half of tasks that would take an expert human roughly that long. Easier tasks have much higher success rates, while harder ones see performance fall off quickly. The model itself often completes these tasks in minutes or tens of minutes, but the difficulty level reflects hours of human effort.
This framing is why METR treats time horizon as a proxy for autonomy. A system that can finish longer human equivalent tasks without intervention is, by definition, acting more independently across multiple steps.
Also read: AI and LLMs still suck at scientific discovery, new study reveals exactly why
What makes the Opus 4.5 result stand out is not just the headline number, but the uncertainty around it. METR reports an unusually wide confidence interval, stretching from under two hours to more than twenty. That signals the model is pushing the upper limits of what the current benchmark can reliably measure. Small changes in task selection or scoring can shift the estimate significantly.
Even so, the broader trend is hard to ignore. Over the past few years, METR and outside analysts have observed that frontier AI systems are steadily extending their time horizons, roughly doubling every few months. Claude Opus 4.5 appears to land at or slightly above that curve, at least at the 50 percent reliability level.
Crucially, this does not mean AI can now replace human workers for half a day at a time. The tasks are controlled, software focused, and stripped of the messy social and contextual factors of real world work. But it does suggest that long horizon, goal driven AI agents are becoming technically plausible.
For researchers and policymakers watching the rise of autonomous systems, five hours of expert level autonomy is less a finish line and more a signpost. It marks how quickly the boundary is moving, and how urgently we need better tools to understand what comes next.
Also read: OpenAI reveals how ChatGPT’s thoughts can be monitored, and why it matters
{kind=link}