NVIDIA’s newest AI server architecture has delivered one of the most significant performance jumps seen this year, unlocking a tenfold efficiency boost for major Chinese models from DeepSeek and Moonshot AI. The gains are not simply the result of faster chips but of a redesigned server layout built to handle the computational demands of mixture of expert models, which are rapidly becoming the preferred architecture for large scale AI systems.
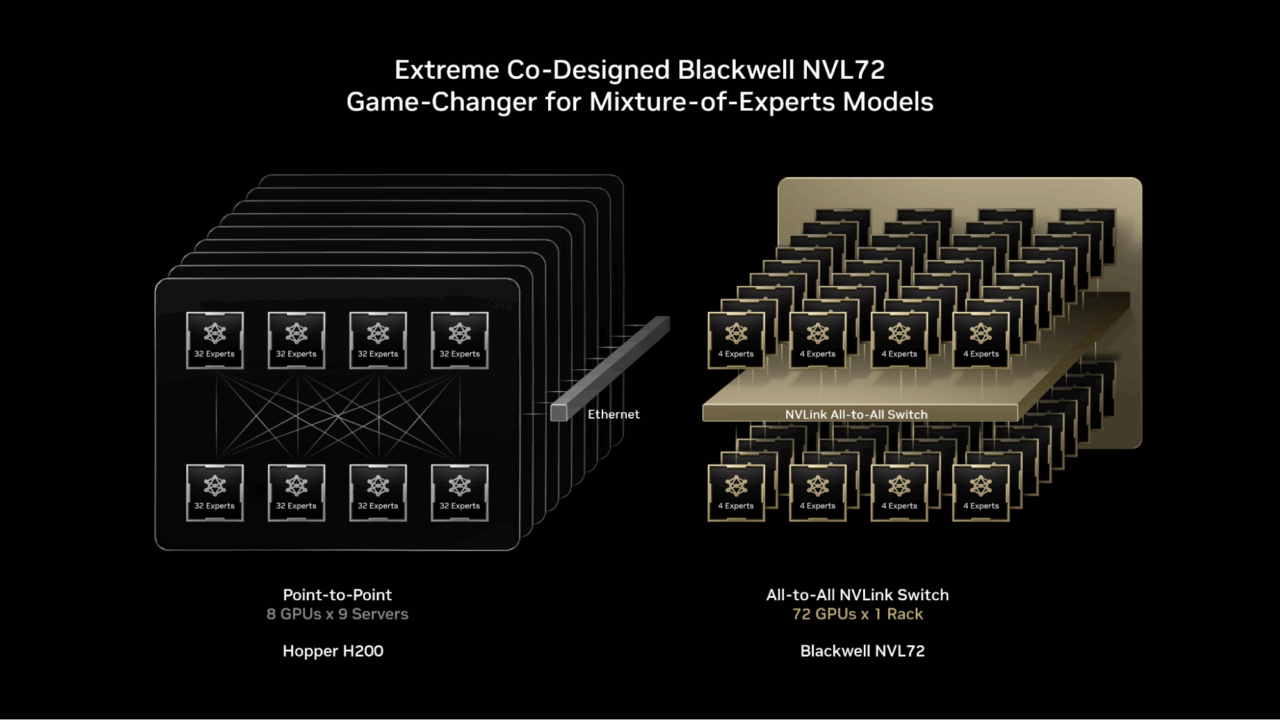
For both DeepSeek and Moonshot AI, the jump came at a crucial moment. Their models are growing in size, complexity and real world use cases, and inference cost has become a major limiting factor. NVIDIA’s new server design aims directly at that pain point. Instead of scaling performance through raw chip power alone, the company created a tightly integrated system where seventy two accelerators communicate through high bandwidth links that minimise bottlenecks during expert routing. The result is a server that can deliver far more throughput without multiplying energy or hardware requirements.
Also read: Workspace Studio explained: AI agents will automate more work, believes Google
Mixture of expert models rely on selecting specialised subnetworks for each token or task. This architecture can be highly efficient, but only when hardware is capable of moving data between chips with very low latency. Traditional servers struggle when experts sit across multiple accelerators, leading to delays every time the model switches paths. NVIDIA’s system is designed to keep communication fast and predictable so that expert selection does not slow down inference.
DeepSeek’s and Moonshot’s models depend heavily on rapid expert switching. Once deployed on the new hardware, they saw faster response times, higher token throughput and significantly lower cost per query. These gains make it easier for them to serve millions of users while keeping operational expenses under control.
The efficiency improvement comes from three engineering choices. First, the dense seventy two chip layout reduces hop distance between accelerators. Second, the server uses a high speed fabric that lets chips share data without congestion during peak load. Third, memory bandwidth and caching have been optimised to reduce repeated data fetches.
Also read: Crucial RAM is dead, blame it on AI: Why Micron is shifting its memory priorities
Together, these changes create a pipeline where MoE models run closer to their theoretical speed. For developers, this means they can deploy larger models or handle higher traffic without adding more servers. For users, it means faster responses and more stable performance even during heavy demand.
The performance leap has wider implications. China’s leading AI firms have been searching for ways to expand their capabilities despite supply constraints. Gains of this magnitude help close the gap with American competitors and highlight how hardware choices can influence national AI progress.
The move also intensifies competition in the server market. AMD and Cerebras are preparing next generation systems, and cloud providers want hardware that can run massive models with lower energy costs. NVIDIA is positioning its new server as the answer to this demand and as the foundation for a future where MoE architectures dominate the landscape.
Efficiency is becoming as important as raw power. DeepSeek’s and Moonshot’s results show how much can change when hardware is tuned for the models that define modern AI. NVIDIA argues that these systems will become the new standard. If the early numbers are any indication, the next wave of AI will be shaped as much by server design as by model innovation itself.
Also read: Claude 4.5 Opus ‘soul document’ explained: Anthropic’s instructions revealed
{kind=link}
{kind=link}