The race to build the ultimate AI coding agent has entered a more mature, more revealing phase. With fresh releases from Anthropic and OpenAI, the competition is no longer about flashy demos or clever code completion. It is about sustained autonomy, real execution, and whether these systems can genuinely behave like software engineers rather than autocomplete engines.
At the center of the moment are Claude Opus 4.6 and GPT-5.3 Codex. Both push the idea of an “agent” further than before. Both claim meaningful progress. And both reveal sharply different ideas of what leadership in this space actually looks like.
Also read: Claude Opus 4.6 explained: 5 major upgrades you should know about
Claude Opus 4.6’s most decisive advantage is not subtle. It supports a 1 million token context window, giving it a rare ability to ingest entire large codebases, sprawling documentation sets, or long chains of prior reasoning in a single session. For teams dealing with legacy systems or complex monorepos, this is not a convenience feature. It is a structural edge.
Anthropic pairs that scale with a strong showing on reasoning-heavy benchmarks. Claude Opus 4.6 leads on SWE-bench Verified and similar evaluations that reward understanding intent, navigating ambiguity, and producing correct fixes rather than simply executing commands. In practical terms, this shows up in tasks like multi-file refactors, architectural reasoning, and debugging that requires understanding why a system exists, not just how it runs.
Anthropic also emphasizes duration. While it avoids flashy claims, Opus 4.6 is positioned as capable of sustained agentic focus across long sessions. The implication is that the model can stay coherent over extended problem-solving windows without drifting or losing context, an increasingly important trait as developers ask agents to work independently for longer stretches.
Claude’s pitch is clear. If coding agents are going to resemble senior engineers who read everything, think deeply, and make careful changes, this is the direction to go.
GPT-5.3 Codex comes from a different instinct. OpenAI is optimizing for doing, not just thinking.
Also read: OpenAI brings GPT 5.3 Codex model and Frontier platform: What it means for AI users
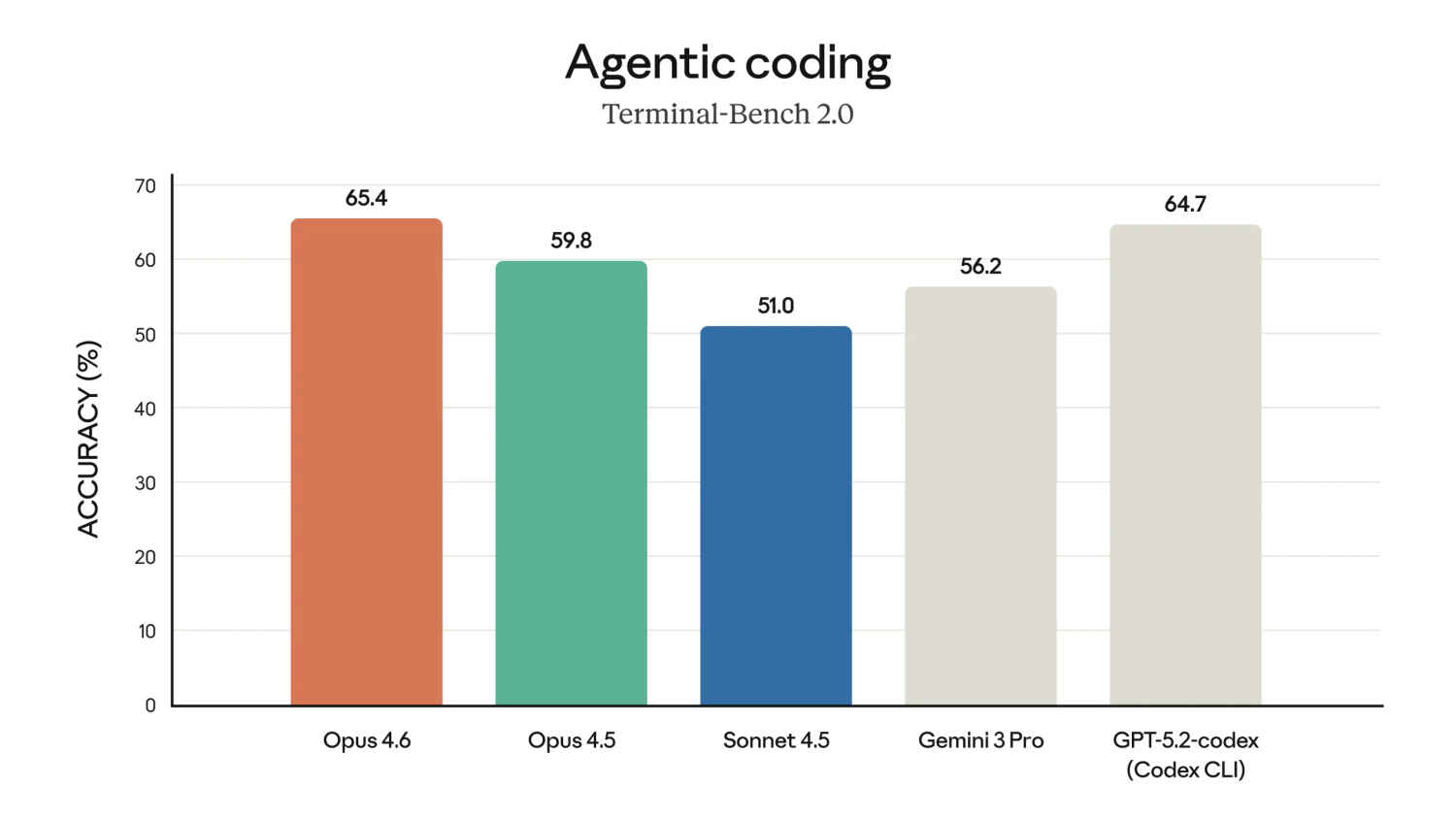
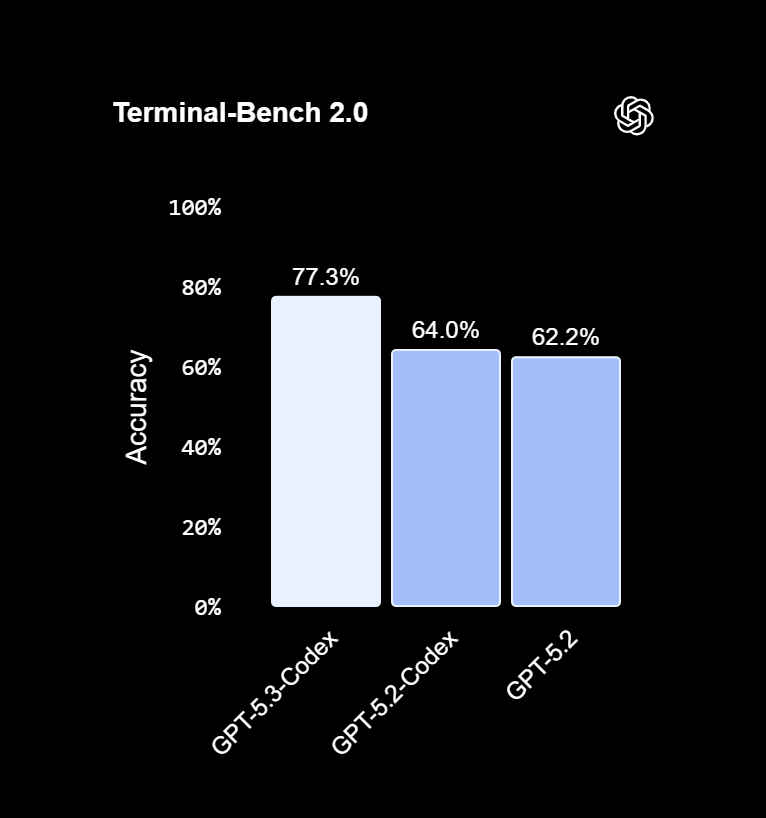
The model is designed to handle long-running tasks that involve writing code, running it, inspecting results, and iterating repeatedly. OpenAI says GPT-5.3 Codex is faster than earlier versions and better suited to tool-heavy workflows where execution speed and tight feedback loops matter. This philosophy shows up clearly in benchmarks like Terminal-Bench and OSWorld, where GPT-style agents tend to outperform more reasoning-focused models.
OpenAI has also highlighted that Codex-class models were used internally to assist with parts of their own development and debugging processes. That detail matters. It signals a belief that coding agents should live inside real production environments, not just chat interfaces, and that success should be measured by completed tasks rather than elegant reasoning traces.
GPT-5.3 Codex also supports long task durations, building on earlier Codex generations that could operate over extended periods. The emphasis here is persistence through execution rather than depth of context ingestion.
If Claude feels like a staff engineer reading the whole repo before touching anything, GPT-5.3 Codex feels like a senior developer who starts running commands immediately and fixes things in motion.
On paper, there is no outright winner. Claude Opus 4.6 leads on reasoning and verified code-fix benchmarks. GPT-5.3 Codex leads on execution-focused tasks and environment interaction. Each model dominates where its philosophy is strongest.
That makes the broader conclusion unavoidable. Leadership in the coding agent race is no longer a single axis. It depends on whether the future of software development prioritizes deep contextual understanding or rapid, tool-driven execution.
What is certain is that the race has moved past autocomplete. The real contest now is about trust. Who can build an agent that developers are comfortable leaving alone with real systems, real stakes, and real time. Right now, both Anthropic and OpenAI are winning different versions of that future.
Also read: Indian fintech under increased cyber attacks: DDoS, data breaches rise sharply
{kind=link}
{kind=link}