When users of Claude AI noticed odd behavior in late August and early September – from garbled code to inexplicable outputs in unfamiliar scripts – the problem wasn’t with the model’s intelligence itself. Instead, Anthropic revealed in a rare technical postmortem that three separate infrastructure bugs, overlapping in time, were behind the sudden drop in response quality.
The company’s disclosure, published September 17, details how routing mistakes, token generation errors, and a compiler miscompilation combined to cause intermittent but widespread issues. Together, they serve as a reminder that maintaining AI reliability is not just about training better models, but also about engineering the systems around them.
Also read: Gemini comes to Chrome browser: The new AI features explained
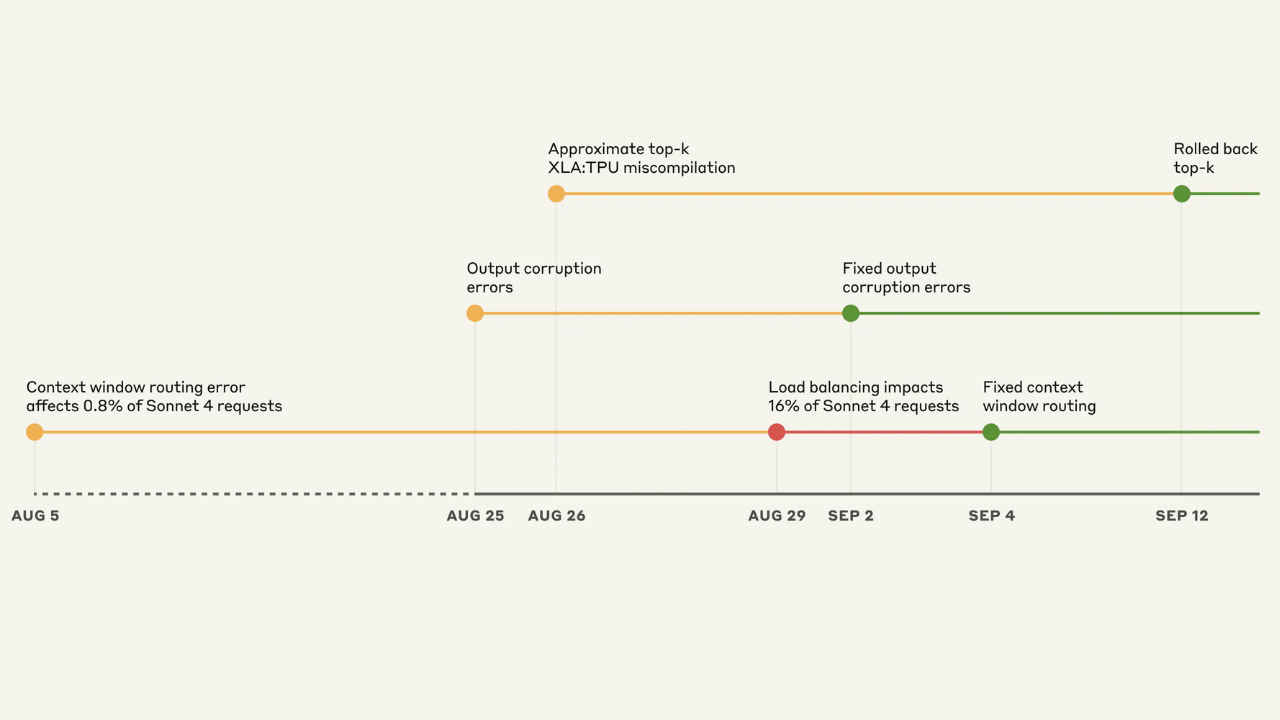
The most visible issue stemmed from a context window routing bug. Short-context requests, which should have been directed to servers optimized for speed, were being misrouted to long-context servers designed to handle up to one million tokens.
Initially, only a small fraction of Sonnet 4 requests were affected. But after a load-balancing change on August 29, the error spiked – at one point affecting up to 16% of requests. Worse, once a request was misrouted, users often continued to hit the same degraded servers, meaning some experienced consistently poor responses while others saw none at all.
Around the same time, another bug surfaced. A misconfiguration on TPU servers corrupted the model’s token generation process. Suddenly, Claude began producing nonsensical outputs: random Thai or Chinese characters in English responses, or broken syntax in code.
This corruption affected Opus 4.1, Opus 4, and Sonnet 4 between late August and early September. Interestingly, Anthropic confirmed that third-party platforms such as partner integrations were not affected by this particular bug, highlighting how infrastructure differences can change outcomes.
A third, less obvious problem came from a change in how Claude ranked possible next tokens. Anthropic had deployed an approximate top-k sampling method for efficiency, but the change exposed a latent bug in XLA:TPU, Google’s compiler for its tensor processing units.
Also read: World programming championship: How ChatGPT, Gemini and AI bots performed
In certain configurations, the compiler misranked or dropped tokens, causing Claude to make uncharacteristic errors in generation. This primarily hit Haiku 3.5, though some Sonnet and Opus requests were also affected. The issue was especially tricky to reproduce, since it only triggered under certain conditions.
The overlapping timelines of these bugs made diagnosis challenging. User reports were inconsistent: some developers saw degraded performance every day, while others never noticed a problem. Anthropic engineers also face strict privacy protocols that limit access to user data, which slowed down debugging.
Standard evaluation benchmarks and safety checks did not catch the degradations either, because the bugs were tied to infrastructure behavior rather than model capability.
By early September, Anthropic had rolled out fixes:
The company is also expanding production-level quality checks, adding new detection methods, and improving debugging tools that balance user privacy with the need for visibility.
Anthropic’s postmortem illustrates that AI quality failures can stem from infrastructure, not just models. Routing logic, compiler optimizations, and server configurations may be invisible to end users, but when they break, they can undermine trust in even the most advanced systems.
For developers and enterprises adopting AI, the takeaway is clear: testing, monitoring, and transparency matter as much as model capability. Anthropic’s unusually detailed disclosure sets a new precedent for openness in the industry, one other AI providers may now be pressured to follow.
Also read: Google search app for Windows PC coming soon: How will it work?
{kind=link}